
What Is a Machine Learning Scientist? (Updated for 2025)


Overview
The title Machine Learning Scientist gets thrown around a lot, and it’s often confused with Data Scientist, but anyone specializing in machine learning knows there’s a clear difference.
A machine learning scientist is often a research and development role unlike a data scientist. The machine learning scientist typically focuses on researching new ML methods and algorithms and generating new or improved ways for a company to utilize machine learning techniques.
For example, at Amazon, machine learning scientists are responsible for:
“Researching and developing algorithms that are used in adaptive systems across Amazon. They build methods for predicting product suggestions and demand, exploring Big Data to automatically extract patterns.”
Ultimately, the role and title vary by company. At Meta, for instance, they’re called Research Scientists; at Microsoft, they’re known simply as Researchers. You’ll also find a lot of machine learning scientists in academia.
However, no matter the industry, the job role is similar: researching and developing new and existing ML techniques.
What’s the Difference Between a Machine Learning Engineer and a Machine Learning Scientist?
Machine learning engineers and scientists share a lot of the same skills. Both roles require in-depth knowledge of algorithms, Python and SQL, and software engineering. Yet, there are key differences in both job function and skillset:
Job Function
A machine learning engineer deploys machine learning algorithms and models and maintains and scales ML models in production.
On the other hand, a machine learning researcher focuses on advancing a niche subject domain within machine learning, like natural language processing, deep learning, computer vision, or finding a new approach to a business problem. For example, an ML scientist might be responsible for modifying an existing ML library or writing and developing a new library.
Skills
Machine learning engineers and scientists require many of the same technical skills: Python, SQL, algorithms, etc.
The key difference is that machine learning scientists tend to have strong backgrounds in research (which is why many are PhDs). They must know how to conduct experimental and quasi-experimental trials and are skilled at documenting and presenting research.
Another difference is that machine learning researchers tend to have more specialized ML knowledge within a particular domain, like probabilistic models or the Gaussian process.
Data Scientist vs Machine Learning Researcher: Key Differences
Data scientists and machine learning researchers share many of the same job functions. In fact, in some companies, machine learning scientists are called simply data scientists.
But there are some key differences between the roles.
Data scientists, for example, are usually responsible for building models and presenting results to stakeholders. Their key goal is deriving business value from data, whereas in many research roles, the goal is completing a study and getting insights from research.
Although there is an overlap in skills, research roles also tend to require:
- A PhD
- More specialized backgrounds (Robotics, physics, AI, or computer vision)
- Experience with experimental design
- Software engineering skills (like C++ or Java)
Ultimately, the researcher is usually singularly focused on a complex problem, like improving self-driving tech, and therefore, they tend to have a specialized background in that domain area. On the other hand, a data scientist tends to have broad knowledge in data science but not necessarily deep domain expertise.
How to Become a Machine Learning Scientist
These roles almost always require a PhD. In fact, we analyzed the LinkedIn profiles of machine learning scientists and researchers. We found that:
- 93%+ had a PhD (most commonly in computer science, statistics, mathematics, or machine learning)
- 95% had a master’s degree
- On average, ML researcher jobs require 5-7 years of experience
This isn’t always the case. For example, research scientist roles at Toyota require a bachelor’s or master’s in a quantitative field, while a Ph.D. in machine learning, robotics, or computer vision is a preferred qualification.
Transitioning from Academia
Many ML scientists make the switch from academia. In fact, almost all FAANG companies hire extensively from Ph.D. programs.
For some, it can be a tough transition, and PhDs should be prepared for several cultural and technological differences between university and private company research environments. They include:
- Collaboration - Ph.D. candidates tend to work in small teams or alone. In private companies, the ability to collaborate with diverse stakeholders is a necessity.
- Data - PhDs often work with fixed datasets and might not even deploy their model at scale. As an ML researcher, the model must be tested, scaled, and monitored long-term. The datasets are also constantly evolving.
- Changing Goals - In academic research environments, the goal is to generate the research result. You start with a problem statement and study it. In business, the project may evolve as the needs and leadership change within the company.
Ultimately, many from an academic background enjoy private research environments, as they’re continually challenged and paid well to work on interesting, cutting-edge tech.
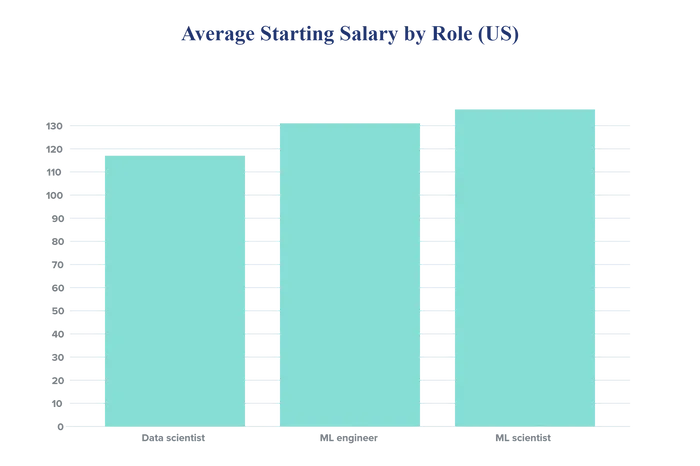
Here’s a look at the average salary by role:
Example Machine Learning Scientist Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
Write a SQL query to select the 2nd highest salary in the engineering department. Note: If more than one person shares the highest salary, the query should select the next highest salary. Example: Input:
Output:
| ||||||||||||||||||||||||
Data Structures & Algorithms | Easy | |||||||||||||||||||||||
A/B Testing | Medium | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Interviews for machine learning roles tend to dive deep into ML techniques and methodologies. You’ll face ML algorithm questions and Python ML questions, as well as machine learning system design and case studies questions.
Here are some examples of the types of questions you might face in a machine learning interview:
1. How would you interpret coefficients of logistic regression for categorical and boolean variables?
The sign of the coefficient is important. If you have a positive sign on the coefficient, then that means that all else is equal, the variable has a higher likelihood of positively influencing your outcome variable.
2. Write a function compute_deviation that takes in a list of dictionaries with a key and a list of integers and returns a dictionary with the standard deviation of each list.
Note: This should be done without using the NumPy built-in functions.
Before jumping into this deviation coding problem, define how you will compute the standard deviation without using the NumPy function. This means we must build a function to calculate the standard deviation through the formula.
3. Write a function decreasing_values to return an array of integers so that the subsequent integers in the array get filtered out if they are less than an integer in a later index of the array.
This Python array problem is difficult because it seems like it requires logic around addition and deletion from an array. The problem states that we want continuous decreasing values from the first element in the array until the end.
4. How would you tackle multicollinearity in multiple linear regression?
Multiple linear regression is a method that uses several independent variables to predict or explain the dependent variable we are interested in. When using this technique, we assume that the independent or explanatory variables are also independent of one another (i.e., the values do not affect one another).
5. Build a k Nearest Neighbors classification model from scratch.
Note: Use Euclidean distance as your closeness metric. You may not use the Scikit-learn library.
This KNN question requires you first to define the metric. In this case, we know it’s Euclidean distance. Then, you would define a helper to calculate the distance between and every data point in our data frame.
6. How would we give each rejected applicant a reason why they got rejected?
What if we had rejected an applicant with a recurring outstanding credit card balance of 10% of their monthly take-home income?
How could we use this data point to help us map towards understanding if this feature was a helpful indicator or not when we have a sample distribution of application outcomes?
7. How would you write a query to get an employee’s current salary?
Due to an ETL error, the employees’ table did an insert instead of updating the salaries when making compensation adjustments.
The first step we need to take is to remove duplicates and retain the current salary for each user.
Given that there aren’t any duplicate first and last name combinations, we can remove duplicates from the employees’ table by running a GROUP BY on two fields, the first and last name. This allows us to then get a unique combinational value between the two fields.
8. Given N samples from a uniform distribution [0,d], how would you estimate d?
What does a uniform distribution look like? Just a straight line over the range of values from 0 to d, where any value between 0 to d is equally likely to be randomly sampled.
So, let’s make this easy to understand practically. If we’re given N samples, and we have to estimate what d is with zero context of statistics, and based on intuition, what value would we choose?
9. Why would the same machine learning algorithm generate different success rates using the same dataset?
When they ask us an ambiguous question, we need to gather context and restate it clearly for us to answer.
When it says “same dataset,” this could mean the same training dataset the same testing dataset, or both.
In any of these cases, it could also be asking about the dataset available for the model or the dataset the model uses. These two datasets could be different. For example, different sampling methods over the same available training data could have our model use different data points.
Learn More about Machine Learning Algorithms
This course is designed to help you with everything you need to know about Machine Learning Algorithms:
More Machine Learning Scientist Resources
Check out these resources from Interview Query to learn more about machine learning scientist interviews: