
Roblox Data Engineer Interview Guide: Process, Questions & Preparation (2026)


Introduction
Data engineering continues to be one of the fastest growing technical career paths, with the U.S. Bureau of Labor Statistics projecting more than 35% growth across data roles through 2032. This acceleration is fueled by the rise of large scale real time systems, more complex analytics stacks, and the increasing importance of trustworthy data across product, safety, and infrastructure teams. Roblox supports tens of millions of daily active users and processes massive streams of gameplay, social, and safety related events every second, which requires data engineers who can build highly reliable and extremely performant pipelines.
This level of scale also means competition is steep. Industry estimates suggest that well under 15 percent of applicants in data engineering roles at major consumer platforms make it past the initial screening, especially as teams prioritize experience with distributed systems, streaming architectures, and high quality ETL design. Many candidates struggle because they are unsure of what Roblox emphasizes in its interviews or how to present their experience in a way that aligns with the company’s engineering culture. This guide breaks down every stage of the Roblox data engineer interview, outlines the most common Roblox specific interview questions, and provides clear, practical strategies to help you prepare efficiently and confidently with Interview Query.
Roblox Data Engineer Interview Process
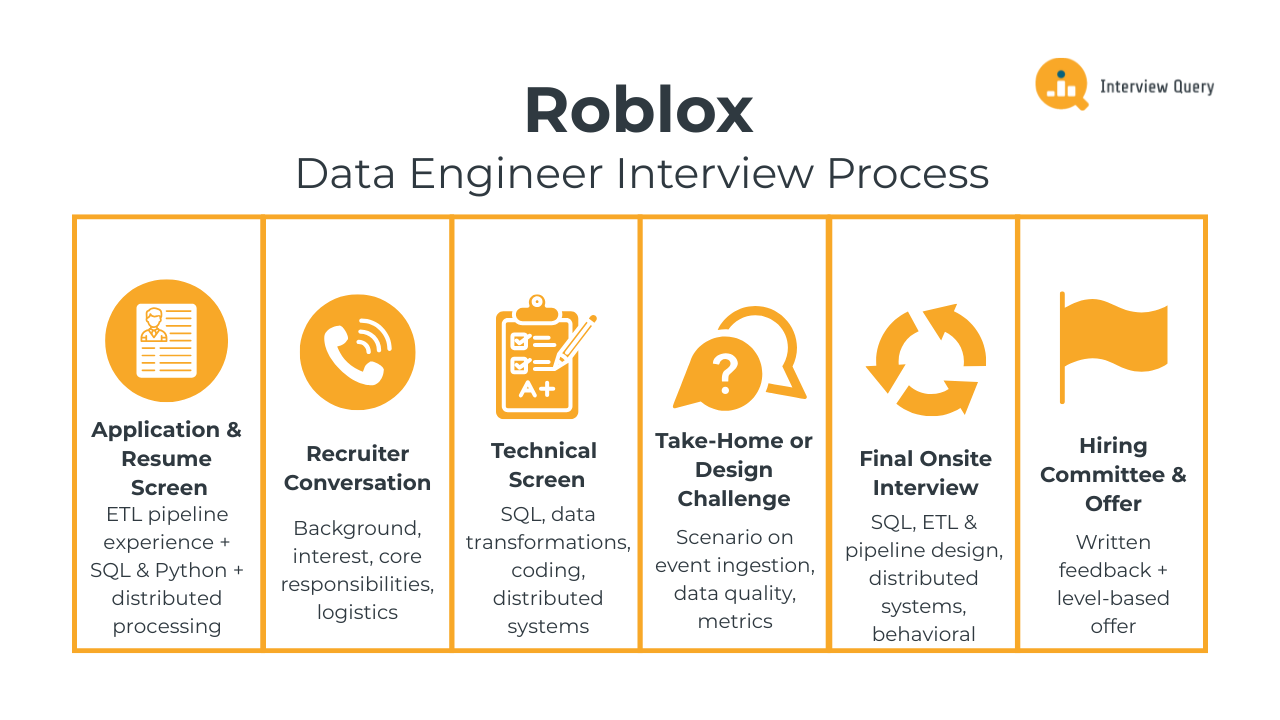
The Roblox data engineer interview process evaluates your ability to design reliable data pipelines, reason about large scale distributed systems, and maintain high quality data under real time constraints. Roblox places a strong emphasis on engineering rigor given the scale of its platform, where millions of user interactions generate continuous streams of gameplay, social, and safety related events. Most candidates move through four to six stages that assess technical depth, practical design skills, and alignment with Roblox’s values around safety, collaboration, and user centric engineering. Below is a breakdown of each step and what Roblox interviewers typically look for throughout the process.
Application and Resume Screen
During the application review, Roblox recruiters look for experience building scalable ETL pipelines, strong SQL and Python or Scala skills, and familiarity with distributed processing frameworks such as Spark. Backgrounds that include streaming infrastructure, data quality engineering, or real time event systems stand out because they align closely with Roblox’s platform demands. Recruiters also prioritize candidates who highlight measurable impact, such as improvements in latency, reliability, data availability, or tooling that enabled downstream teams to make better decisions.
Tip: Quantify scale and blast radius, not just tools. Roblox recruiters look for signals like events per day processed, pipeline latency reductions, incident frequency improvements, or how many downstream teams relied on your systems. Numbers tied to reliability matter more than listing technologies.
Initial Recruiter Conversation
The recruiter call is a short introductory discussion about your background, interest in Roblox, and experience with core data engineering responsibilities. You may be asked about prior work with batch and streaming systems, your approach to ensuring data accuracy, and your familiarity with Roblox’s mission around safe user experiences. This round also covers logistics such as location preferences, work authorization, and compensation expectations. It is non technical but determines whether your experience aligns with the needs of the team.
Tip: Frame your experience around problems Roblox cares about. Explicitly connect your past work to untrusted client data, real time telemetry, or safety critical systems. Recruiters are listening for alignment with Roblox’s platform challenges, not generic data engineering buzzwords.
Technical Screen
The technical screen typically consists of one or two interviews focused on SQL, data transformations, coding, and foundational distributed systems concepts. You may be asked to write queries that compute event based metrics, optimize transformations, or clean and validate messy logs. Coding tasks often involve manipulating nested data structures, implementing ETL logic, or reasoning through Spark operations. Interviewers look for clear logic, clean code, and the ability to communicate decisions while thinking through trade offs.
Tip: Narrate your reasoning as you code. Roblox interviewers care deeply about how you think through edge cases, data correctness, and trade offs. Silence while typing is a missed opportunity to demonstrate judgment and production awareness.
Take Home Assignment or Data Engineering Design Challenge
Some teams include a take home assessment that presents a scenario involving event ingestion, data quality issues, or metrics computation. You may be asked to propose a pipeline architecture, explain how you would handle schema changes, or outline how you would process late arriving data. Submissions are evaluated on clarity, structure, and practical reasoning rather than completeness alone. A well structured explanation of assumptions and validation steps is crucial.
Tip: Optimize for clarity, not completeness. Strong submissions clearly state assumptions, failure modes, and validation strategies. At Roblox, engineers are expected to document reasoning so others can operate and trust the system long after it ships.
Final Onsite Interview
The final onsite loop typically includes four to five interviews covering coding, SQL, ETL design, distributed systems, and behavioral alignment. Each round evaluates different aspects of your engineering approach, communication style, and ability to collaborate across teams.
SQL and data analysis round: Expect to write queries that analyze player behavior, detect anomalies in event streams, or compute rolling metrics. Interviewers assess your ability to structure complex joins, use window functions effectively, and think critically about data completeness and quality.
Tip: Always clarify event semantics before querying. Roblox interviewers expect you to ask what constitutes a session, login, or action because incorrect assumptions are a common cause of production data issues.
ETL and pipeline design round: You may be asked to design an ingestion pipeline, outline how you would process billions of events per day, or suggest strategies for backfilling missing data. Interviewers look for reasoning around scalability, reliability, idempotency, and schema evolution.
Tip: Explicitly call out how you would detect silent failures. Interviewers are listening for monitoring strategies like volume baselines, freshness checks, and skew detection, not just pipeline architecture.
Distributed systems round: This round evaluates how you approach real time systems, partitioning strategies, consistency guarantees, and job optimization. You may be asked about Spark internals, handling skew, or ensuring exactly once processing for critical events.
Tip: Anchor your answers in real failure scenarios. Discuss hotspots after viral launches, late events from mobile clients, or backpressure during traffic spikes. Roblox values engineers who design with volatility in mind.
Behavioral and collaboration round: This interview explores how you work across teams, navigate ambiguity, and handle production issues. Roblox values engineers who communicate clearly, take ownership, and prioritize safety in user facing environments.
Tip: Quantify impact wherever possible. Replace vague outcomes with metrics such as reduced incident counts, faster recovery times, or improved data accuracy. Roblox interviewers consistently favor candidates who can tie behavior to measurable outcomes.
Hiring Committee and Offer
After the onsite, interviewers submit written feedback that is reviewed collectively by a hiring panel. The committee evaluates your performance across all technical and behavioral areas and determines whether you meet Roblox’s engineering bar. If approved, the team assigns a level and prepares an offer that reflects your experience, role fit, and the needs of specific teams such as Trust and Safety, Creator Analytics, or Platform Infrastructure.
Tip: Be transparent about your interests and strengths. Roblox teams differ significantly in focus, and sharing where you do your best work helps hiring committees place you where you can have the highest impact.
Want to build up your data engineer interview skills? Practice real hands-on problems on the Interview Query Dashboard and start getting interview-ready today.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Roblox?
Roblox Data Engineer Interview Questions
The Roblox data engineer interview questions are designed to evaluate how well you understand real world data challenges at platform scale, including processing massive event streams, maintaining schema integrity, debugging system failures, and producing trustworthy metrics for safety and creator analytics. Roblox interviewers focus on both your technical execution and your ability to structure ambiguity, communicate trade offs, and demonstrate engineering rigor in fast moving environments.
Read more: Data Engineer Interview Questions and Answers
SQL and Analytics Interview Questions
In this stage of the interview, Roblox evaluates your ability to work with high volume event data, derive engagement metrics, debug anomalies, and structure complex queries. SQL questions often involve window functions, deduplication logic, time based segmentation, or event stream validation. The goal is to assess whether you can reason cleanly about data correctness, ordering, and completeness while working with logs that reflect real user behavior.
Write a query to detect overlapping subscription periods
This question tests interval reasoning, temporal joins, and your ability to detect conflicting time windows, which is essential at Roblox for identifying billing inconsistencies or overlapping premium benefit periods that may affect creator payouts or subscription analytics. You solve it by self joining the subscription table on customer ID where one subscription’s start date falls before another’s end date and the second subscription’s start date falls before the first one ends, while excluding self matches.
Tip: At Roblox scale, interval bugs often surface only at boundaries. Call out how you would normalize time zones, handle open ended subscriptions, and guard against duplicate ingestion from client retries. Interviewers want to see that you think beyond the query and consider how upstream data issues can silently create overlaps.
Given a table of gameplay events, identify users who show sudden spikes in session length compared to their previous week’s average.
This question evaluates anomaly detection through SQL, which Roblox uses to flag potential bot behavior, gameplay glitches, or sudden shifts in experience performance. Solve it by computing per user daily or per-session durations, using window functions to calculate a seven day rolling average, then comparing each session’s duration to that baseline and filtering for unusually large deviations.
Tip: Explicitly explain how you would exclude AFK sessions, crash loops, or reconnect artifacts. At Roblox, session anomalies are frequently data quality issues, not real behavior, and strong candidates demonstrate skepticism toward raw telemetry before trusting aggregates.
-
This question tests your ability to interpret behavioral engagement patterns, which Roblox monitors to understand retention and user health across experiences. You solve it by ordering each user’s visit dates, using
LAG()to detect breaks in consecutive days, assigning streak IDs when gaps occur, aggregating streak lengths per user, and selecting the top five.Tip: Always clarify what counts as a “visit” at Roblox. Is it an app open, a session start, or an experience join? Calling this out shows you understand that engagement metrics depend heavily on event semantics, not just SQL mechanics.
Head to the Interview Query dashboard to practice the full set of Roblox interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for Roblox’s data engineering interviews.
Calculate how many users logged in an identical number of times on January 1st, 2022.
This question tests your understanding of nested aggregations and frequency distributions, which Roblox uses for monitoring platform load, peak concurrency, and behavior clustering. Solve it by first counting logins per user for the date, then grouping those counts to determine how many users share each login frequency. This highlights your ability to summarize user level behavior into platform level insights.
Tip: Mention how you would validate this result against known traffic patterns like holidays, outages, or releases. Roblox interviewers value engineers who sanity check metrics against real world context instead of treating numbers as inherently correct.
Write a query to compute creator payout totals grouped by experience and region.
This question tests your ability to join monetization tables with experience metadata, crucial at Roblox where creator earnings drive platform economics. Solve it by joining transactions or payout events to experience and region data, grouping by both attributes, and summing earnings while handling missing or null fields to ensure accurate payouts.
Tip: Call out that you would never compute payouts directly from raw events without reconciliation. At Roblox, payouts are sensitive, audited metrics, so interviewers expect you to mention currency normalization, late adjustments, and validation against finance owned sources.
Want to get realistic practice on SQL and data engineering questions? Try Interview Query’s AI Interviewer for tailored feedback that mirrors real interview expectations.
Data Pipeline and ETL Design Interview Questions
Roblox tests your understanding of how to design ETL systems that ingest billions of events daily. These questions evaluate reasoning around scalability, data freshness, quality checks, and schema evolution.
How would you design an ETL pipeline to process real time gameplay telemetry at scale?
This question tests your ability to design end to end pipelines under extreme scale, which is core to Roblox’s platform where millions of gameplay events arrive continuously. Roblox asks this to evaluate how you reason about ingestion reliability, transformation efficiency, and downstream usability. A strong answer outlines a streaming first ingestion layer, partitioned processing by experience or user, durable storage for raw and processed data, and monitoring for lag and data loss.
Tip: At Roblox, the real risk is silent degradation, not total failure. Call out how you would track ingestion lag per experience, monitor event volume deltas against historical baselines, and alert on schema drift. Interviewers want to hear that you assume data loss will happen and design systems to detect it quickly.
-
This question evaluates how you handle schema evolution in long lived pipelines, which Roblox faces due to frequent client and feature updates. Roblox asks this to ensure you can protect analytics, safety systems, and creator reporting from breaking changes. You should explain using versioned schemas, backward compatible field additions, validation layers, and clear ownership of schema contracts between producers and consumers.
Tip: Explicitly mention ownership and contracts. At Roblox scale, schema problems are organizational failures as much as technical ones. Strong candidates explain how they enforce schema reviews, publish change timelines, and validate new fields in shadow pipelines before full rollout.
Head to the Interview Query dashboard to practice the full set of Roblox interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for Roblox’s data engineering interviews.
How would you handle late arriving or out of order events when computing daily metrics?
This question tests your understanding of event time versus processing time, which is critical for accurate Roblox metrics like retention, safety signals, and payouts. Roblox asks this because client connectivity and retries often cause delayed events. A strong answer explains using event timestamps, watermarking, idempotent writes, and periodic backfills to correct aggregates while minimizing reprocessing overhead.
Tip: Mention which metrics tolerate correction and which do not. At Roblox, safety and payouts often require recomputation, while engagement dashboards may accept eventual consistency. Interviewers look for engineers who tailor correctness guarantees based on business impact, not one-size-fits-all logic.
How would you create a schema to represent client click data on the web?
This question tests data modeling fundamentals and your ability to design schemas that support flexible analytics at scale. Roblox asks this to assess how well you balance normalization, extensibility, and performance for client telemetry across platforms. You should describe a schema with clear identifiers, timestamps, session context, event type, and optional metadata fields while keeping the core structure stable for downstream consumers.
Tip: Call out that client events are untrusted by default. At Roblox, clients drop fields, retry aggressively, and change versions frequently. Strong answers mention defensive defaults, optional fields, and server side enrichment to protect downstream analytics from client inconsistencies.
How would you build a pipeline that ensures exactly once processing for safety related user events?
This question evaluates your understanding of consistency guarantees in distributed systems, which is essential for Roblox’s trust and safety workflows. Roblox asks this because duplicate or missed safety events can directly affect user protection. A strong answer explains deterministic event IDs, deduplication at write time, checkpointing, and atomic commits so events are processed once even during retries or failures.
Tip: Emphasize auditability over theoretical guarantees. Roblox safety pipelines must be explainable after the fact. Interviewers expect you to mention replayability, immutable raw logs, and metadata that allows investigators to trace how and when a decision was made.
Watch next: Top 10+ Data Engineer Interview Questions and Answers
For more in-depth practice, check out a collection of 100+ data engineer interview questions with detailed answers. In this walkthrough, Interview Query founder Jay Feng breaks down over 10 core data engineering questions, covering SQL, distributed systems, pipeline design, and data modeling.
Distributed Systems and Infrastructure Interview Questions
These questions assess how you think about scaling, performance, and reliability across large distributed environments. Interviewers focus on your ability to anticipate bottlenecks, manage trade offs, and design systems that remain stable during traffic spikes and partial failures.
How would you manage backpressure in a streaming pipeline that is receiving more events than it can process?
This question tests how you reason about system stability under sustained load, which is critical at Roblox where event volume can spike during launches or viral experiences. Roblox asks this to ensure you can prevent data loss and cascading failures. A strong answer explains detecting backpressure early, scaling consumers horizontally, applying rate limits or buffering upstream, and shedding non critical load while preserving safety and billing events.
Tip: At Roblox, backpressure is rarely uniform. Call out how you would prioritize traffic classes, for example safety and monetization events over engagement telemetry, and how you would degrade gracefully by sampling or delaying non critical streams. Interviewers want to hear that you think in terms of blast radius and business impact, not just throughput.
Describe how you would partition gameplay events for efficient processing and querying.
This question evaluates your ability to balance throughput, cost, and query performance at scale. Roblox asks this because poorly chosen partitions can cause hotspots or slow analytics across billions of events. A good answer discusses partitioning by experience or user to distribute load, layering time based partitions for pruning, and adjusting strategies depending on write heavy versus read heavy workloads.
Tip: Strong candidates explicitly mention revisiting partition strategies over time. At Roblox, what partitions well at low traffic can become a hotspot after an experience goes viral. Calling out adaptive partitioning or periodic rebalancing shows real operational experience, not just initial design thinking.
-
This question tests end to end system design, latency management, and safety awareness, all core to Roblox’s live social features. Roblox asks this to see how you balance real time delivery with moderation. A strong answer outlines low latency message ingestion, fan out via pub sub systems, asynchronous AI moderation with fast fail paths, and client side reconciliation to handle delayed censorship decisions.
Tip: Emphasize that moderation decisions may arrive late or be revised. At Roblox, systems must support retroactive enforcement without blocking the live experience. Interviewers look for candidates who design for correction paths, not just happy path real time delivery.
-
This question evaluates consistency, synchronization, and state management across distributed clients. Roblox asks this because its ecosystem spans mobile, desktop, console, and live experiences. A strong solution describes separating ephemeral reactions from persisted comments, using authoritative counters, eventual consistency for fan out, and reconciliation jobs to correct drift.
Tip: Mention that reaction counts are approximate by design. At Roblox scale, eventual consistency is acceptable for reactions but not for persisted comments. Calling out different consistency models for different data types signals maturity in distributed systems design.
Head to the Interview Query dashboard to practice the full set of Roblox interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for Roblox’s data engineering interviews.
Walk through your approach to debugging a distributed job that intermittently fails.
This question tests your debugging discipline and operational maturity, which Roblox values highly for platform reliability. Roblox asks this to understand how you isolate nondeterministic failures at scale. A strong answer covers reproducing the issue, examining logs and metrics, validating assumptions about data and resources, and using checkpoints or partial replays to narrow failure scope.
Tip: At Roblox, intermittent failures are often data dependent, not code dependent. Strong answers mention slicing failures by experience, region, client version, or traffic source to isolate the issue. Interviewers want to see that you debug by narrowing the problem space systematically, not by trial and error.
Looking for hands-on problem-solving? Test your skills with real-world challenges from top companies. Ideal for sharpening your thinking before interviews and showcasing your problem solving ability.
Behavioral Interview Questions
Roblox values collaboration, ownership, and a strong user centric mindset. These questions assess how you communicate, solve problems, and operate under pressure. They help interviewers understand how you handle ambiguity, collaborate across teams, and make responsible decisions when your work directly affects player safety and platform trust.
Tell me about a time you improved data quality in a complex pipeline.
Interviewers ask this to evaluate your ownership mindset and how you approach reliability in large scale systems. At Roblox, data quality issues can impact safety signals, creator payouts, or user engagement metrics, so engineers are expected to proactively identify and fix root causes.
Sample Answer: In one pipeline supporting engagement metrics, I noticed daily active user counts fluctuating unpredictably. I traced the issue to duplicate events caused by client retries during network instability. I introduced deterministic event IDs, added a deduplication stage, and implemented volume anomaly alerts. As a result, duplicate events dropped by 31 percent and week over week metric variance decreased from roughly 12 percent to under 4 percent.
Tip: Always quantify both the problem and the outcome. Roblox interviewers expect numbers that show scale and comparison, such as before versus after variance, error rate reduction, or downstream impact.
Describe a time you resolved a production issue under tight deadlines.
This question tests how you perform under pressure while maintaining clear communication. Roblox looks for engineers who can stabilize systems quickly without sacrificing long term reliability or cross team trust.
Sample Answer: During a high traffic weekend, a batch job powering creator revenue reports began failing intermittently. I rolled back the most recent deployment to restore service within 20 minutes, communicated status updates every 15 minutes, and then investigated the root cause. I identified a memory regression and implemented resource guards and retry limits. Failures dropped from multiple times per hour to zero, and reporting latency improved by 18 percent the following week.
Tip: Highlight time to mitigation and long term prevention separately. Roblox values engineers who protect the platform first and then fix the system properly.
How would you convey insights and the methods you use to a non-technical audience?
Roblox asks this to assess how well you translate technical work into business impact. Data engineers frequently work with product, safety, and operations partners who depend on clear explanations rather than implementation details.
Sample Answer: While presenting pipeline optimizations to non technical partners, I avoided discussing query plans or infrastructure details. Instead, I showed that processing delays dropped from 48 hours to under 6 hours, enabling same day safety reviews instead of next week interventions. This directly supported faster moderation response times and reduced backlog volume by about 22 percent.
Tip: Tie explanations to decisions that changed because of your work. Roblox interviewers care less about clarity alone and more about whether your communication influenced action.
Head to the Interview Query dashboard to practice the full set of Roblox interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for Roblox’s data engineering interviews.
What do you tell an interviewer when they ask you what your strengths and weaknesses are?
This question evaluates self awareness and growth mindset. Roblox values engineers who understand their strengths and actively work to improve areas that limit team scale.
Sample Answer: One of my strengths is diagnosing data correctness issues across distributed pipelines. I’ve consistently reduced incident recurrence by documenting root causes and prevention patterns. A weakness I identified early was holding onto ownership too tightly. By delegating investigations and formalizing runbooks, I reduced mean time to resolution by about 35 percent while helping newer engineers ramp faster.
Tip: Frame strengths and weaknesses around team impact, not personal traits. Roblox interviewers evaluate how you improve systems and people, not just yourself.
What Does a Roblox Data Engineer Do?
A Roblox data engineer builds the large scale data systems that keep the platform safe, reliable, and personalized for millions of users. The role centers on designing pipelines that capture real time gameplay events, power creator analytics, and support trust and safety initiatives across one of the most active user generated ecosystems in the world. Roblox engineers work across distributed systems, ETL orchestration, data modeling, and performance optimization to ensure that every data flow is accurate, efficient, and available to downstream teams.
How Roblox Data Engineers Turn Work into Impact
| What They Work On | Core Skills Used | Tools And Methods | Why It Matters At Roblox |
|---|---|---|---|
| Real time gameplay and platform telemetry | Streaming systems, partitioning, event modeling | Spark, Scala, Python, Airflow | Powers player engagement metrics and experience performance monitoring |
| Creator analytics and payouts | Data modeling, aggregation logic, correctness guarantees | Batch ETL, reconciliation jobs | Ensures creators are paid accurately and on time |
| Trust and safety data pipelines | Idempotent processing, consistency reasoning | Deduplication, replayable logs, validation layers | Supports moderation, fraud detection, and player protection |
| Data quality and observability | Monitoring, anomaly detection, schema validation | Volume checks, freshness alerts, drift detection | Prevents silent data loss across billions of events |
| Cross functional data infrastructure | Communication, system design, ownership | Shared datasets, documentation, SLAs | Enables product, analytics, and safety teams to move faster with confidence |
Tip: Roblox data engineers are evaluated on judgment as much as technical skill. In interviews, emphasize how you design for failure, handle untrusted client data, and protect critical metrics like safety signals or payouts. Demonstrating how your systems prevent silent errors often matters more than raw throughput or query performance.
Want to master the full data engineering lifecycle? Explore our Data Engineering 50 learning path to practice a curated set of data engineering questions designed to strengthen your modeling, coding, and system design skills.
How to Prepare for a Roblox Data Engineer Interview
Preparing for the Roblox data engineer interview requires a focused approach that blends strong engineering fundamentals with clear communication and thoughtful problem solving. Roblox evaluates how well you reason about scale, reliability, and data correctness while working across teams that depend on trustworthy systems. A concise, targeted preparation plan will help you show up confident and ready for every stage.
Strengthen your distributed systems intuition: Focus on fundamentals like partitioning, checkpointing, backpressure, and idempotent processing rather than memorizing tool specific behaviors. Roblox interviewers look for engineers who understand how large systems behave under real time load.
Tip: When practicing system design, always ask yourself what breaks first at 10x traffic. Interviewers are listening for how you reason about failure modes, not just steady state design.
Prioritize data reliability thinking: Build comfort designing validation checks, handling late or out of order events, and ensuring consistency across streaming and batch paths. These themes appear frequently in Roblox design rounds.
Tip: Practice explaining how you would detect silent failures, such as volume drops or skewed distributions. At Roblox, unnoticed data loss is more dangerous than visible pipeline failures.
Improve your architectural communication: Interviews assess how clearly you explain trade offs, constraints, and decision paths. Concise, logical explanations show maturity and engineering judgment and seniority.
Tip: State what you are optimizing for before proposing a solution. Roblox interviewers expect you to explicitly call out whether you are prioritizing correctness, latency, cost, or safety.
Prepare for ambiguity with hypothesis driven reasoning: Roblox often presents scenarios with incomplete information. Practice forming hypotheses, asking clarifying questions, and outlining next steps instead of rushing to solutions.
Tip: Treat ambiguity as expected, not a trick. Strong candidates verbalize assumptions and show how they would validate them using data or metrics.
Run full practice loops to build consistency: Simulating multiple rounds in sequence using realistic mock interviews helps you refine your pacing, communication, and ability to think clearly under pressure.
Use Interview Query’s Question Bank for Roblox style pipelines, or join the Coaching Program for deeper architectural feedback.
Tip: After each mock, write down one reasoning mistake and one communication improvement. Roblox interviews reward consistency across rounds more than isolated strong answers.
Struggling with take-home assignments? Get structured practice with Interview Query’s Take-Home Test Prep and learn how to ace real case studies.
Average Roblox Data Engineer Salary
Roblox data engineers earn competitive compensation packages that reflect the company’s focus on scaling real time data infrastructure, supporting trust and safety systems, and enabling creator analytics at massive volume. Total compensation varies significantly by level, scope of ownership, and location, with equity representing a meaningful portion of long term rewards. Engineers working on core platform teams often receive higher equity packages due to their direct impact on reliability and platform wide performance.
Read more: Data Engineer Salary Guide
Tip: Verify your target level with your recruiter early in the process since leveling at Roblox influences not only your compensation band but also expectations around system design and ownership.
Roblox Data Engineer Compensation Overview (2025-2026)
| Level | Role Title | Total Compensation (USD) | Base Salary | Bonus / Performance | Equity (RSUs) | Signing / Relocation |
|---|---|---|---|---|---|---|
| E3 | Data Engineer I (Entry Level) | $140K – $185K | ~$125K–$150K | Performance-based | Standard RSUs | Occasional |
| E4 | Data Engineer II / Mid Level | $185K – $260K | ~$150K–$175K | Performance-based | Moderate RSUs | Case-by-case |
| Senior E5 | Senior Data Engineer | $245K – $335K | ~$170K–$200K | Above-target possible | Larger RSU grants | More common |
| Staff / E6+ | Staff or Lead Data Engineer | $320K – $450K+ | ~$190K–$230K | High performer bonuses | High RSUs + refreshers | Frequently offered |
Note: These estimates are aggregated from Levels.fyi, Roblox public job postings, Glassdoor salary reports, and Interview Query’s internal compensation database.
Tip: Compare compensation ranges across at least two sources and request location specific data. Roblox bands can vary substantially across San Mateo, Seattle, and fully remote roles.
Average Base Salary
Negotiation Tips for Roblox Data Engineers
Negotiating effectively at Roblox means using data driven benchmarks, understanding how equity vests, and knowing how your experience aligns with the company’s engineering needs.
- Confirm your level early: Leveling at Roblox (E3 through E6+) has a major impact on equity and total compensation. Clarify level before negotiating numbers.
- Use verified benchmarks: Anchor your expectations with salary data from sources such as Levels.fyi, Glassdoor, and Interview Query salary data. Reference competing offers or market trends factually and without pressure.
- Factor in location and team: Compensation can shift meaningfully depending on whether you join Trust and Safety, Creator Analytics, or Core Platform teams. Some groups receive higher equity bands due to system critical work.
Tip: Ask your recruiter for a complete breakdown including base, bonus target, RSU value, vesting schedule, refreshers, and any signing incentives so you can compare offers accurately and negotiate confidently.
FAQs
How long does the Roblox data engineer interview process take?
Most candidates finish the process within three to five weeks depending on team availability and the number of technical rounds. Timelines may extend slightly if multiple engineering groups are evaluating your profile or if additional calibration is required.
Does Roblox use online assessments?
Some early career candidates may complete a coding or SQL style assessment, but most mid level and senior data engineering candidates move directly to technical screens. The format varies by team, but assessments typically focus on practical reasoning, not trick questions.
Is gaming experience required to work as a Roblox data engineer?
No. Roblox does not require gaming or game development experience. Strong data engineering fundamentals, distributed systems knowledge, and clear communication matter far more than domain familiarity.
How important is real time systems experience for Roblox?
It is helpful because Roblox processes continuous streams of player and platform events. However, candidates with strong batch processing backgrounds can still succeed if they demonstrate solid fundamentals in scalability, reliability, and data quality reasoning.
What is the difficulty level of Roblox’s SQL questions?
SQL questions are moderately challenging and focus on real world event patterns such as deduplication, retention, anomaly detection, and segmentation. Clear logic and attention to data correctness matter just as much as syntax.
Do I need streaming experience to get hired?
Streaming experience is valuable, but candidates with strong design instincts and a solid understanding of distributed data systems can ramp up quickly. Roblox values engineers who demonstrate clear reasoning over specific tool expertise.
How important are behavioral interviews at Roblox?
Very important. Roblox emphasizes collaboration, clarity, and ownership. Behavioral rounds help interviewers understand how you work with cross functional partners and handle high impact engineering challenges.
Become a Roblox Data Engineer with Interview Query
Preparing for the Roblox data engineer interview means developing strong engineering fundamentals, clear architectural reasoning, and the ability to operate within a fast moving, real time data ecosystem. By understanding Roblox’s interview structure, practicing real world SQL, pipeline design, and distributed systems scenarios, and refining your communication, you can approach each stage with confidence.
For targeted practice, explore the full Interview Query question bank, try the AI Interviewer, or work with a mentor through Interview Query’s Coaching Program to refine your approach and prepare effectively for Roblox’s data engineering hiring process.
Discussion & Interview Experiences