
Reddit Data Scientist Interview Guide (2026): Process, Questions & Preparation


Introduction
With Reddit’s recent IPO spotlighting its fast-growing data licensing business and the company doubling down on AI moderation and machine learning, the data scientist role at Reddit has never been more central to the platform’s strategy. Every day, billions of signals flow through posts, comments, and communities, giving the Reddit data science team a uniquely rich environment to test hypotheses, build models, and influence product direction at scale.
From experimentation frameworks to feed ranking and community health analytics, Reddit’s analytics culture rewards curiosity, rigor, and clear communication. In this guide, you’ll learn what the role actually involves, how the interview process works, the types of questions you should expect, targeted preparation strategies, salary insights, and FAQs tailored specifically to Reddit’s data science org.
What does a data scientist at Reddit do?
A data scientist at Reddit turns rich, real-time community data into insights that guide product, safety, and revenue decisions. The role is both analytical and strategic as data scientists partner with Product, Engineering, Design, Marketing, and Business Development to shape how millions of people discover content and engage on Reddit.
Across teams, the work typically includes:
- Experimentation & causal inference: Designing A/B tests, defining metrics, running meta-analysis, and evaluating long-term effects
- Product analytics: Tracking DAU, retention, session depth, relevance, and community health
- Tooling & measurement: Building ETLs, dashboards, and self-serve analytics that give teams real-time visibility
- Model evaluation: Partnering with ML engineers to assess ranking, targeting, and anomaly-detection models
Reddit employs data scientists across several key domains:
- Consumer/Core Product – feed ranking, recommendations, community health
- User Growth – activation, funnels, SEO traffic, churn
- Ads & Marketplace – targeting, auction optimization, advertiser ROI
- Safety & Moderation – abuse detection, threat signals, enforcement analytics
- Marketplace Integrity – fraud, quality scoring
- Monetization & Economy – memberships, virtual goods, pricing
Challenge
Check your skills...
How prepared are you for working as a Data Scientist at Reddit, Inc.?
Why data science at Reddit?
Data science at Reddit isn’t a back-office function. It actually changes how millions of people interact online. Every decision you make shows up in real conversations, real communities, and real behaviors. And because Reddit isn’t a clean, curated social graph, but a messy, human, interest-driven ecosystem, the work is harder, the signals are noisier, and the analysis is genuinely more interesting.
Teams don’t come to data scientists for “a quick chart.” They come for clarity. You define the metrics people rally around, pressure-test assumptions with solid experiments, and explain what users are really doing in feeds, comments, onboarding flows, ad auctions, or safety systems. Your insights shape ranking, community health, advertiser value, basically, the way Reddit works at scale.
Reddit values open debate, data transparency, and thoughtful experimentation, giving data scientists meaningful ownership. With flexible work, strong learning budgets, and a culture centered on psychological safety, Reddit is one of the few places where analytical rigor directly shapes the character and health of online communities at scale.
Reddit data scientist interview process
The Reddit data scientist interview process evaluates your analytical depth, communication skills, and ability to make clear decisions with data across Reddit’s product surfaces. The stages below reflect the process used across teams such as Growth, Consumer, Ads, and Safety.
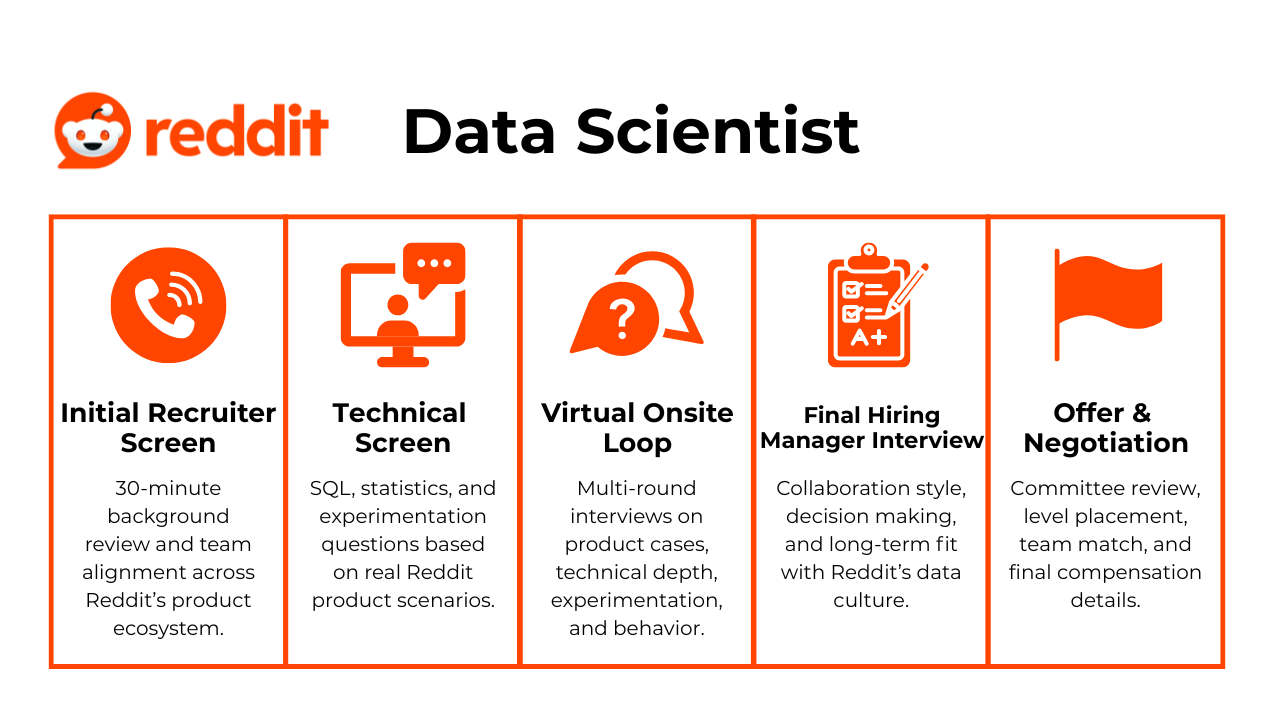
Stage 1: Recruiter screen
This 30-minute conversation focuses on your background, domain alignment, and interest in Reddit’s product ecosystem. Expect questions about past experimentation work, your familiarity with Reddit communities, and which team you are most aligned with. Recruiters often look for signs that you understand Reddit’s mission and the challenges of analyzing user behavior across diverse communities. This is also where timelines and compensation expectations are discussed.
Expert tip: Before the call, read recent posts on the Reddit Engineering Blog. Mention a feature or experiment you found interesting and connect it to your experience. Recruiters use this as a signal to match candidates with teams that value their domain strengths. Practice tailored recruiter screens with Interview Query’s AI Interviewer.
Stage 2: Technical assessment
This stage evaluates your core toolkit across SQL, statistics, experimentation, and product analytics. SQL questions may involve retention, funnels, or anomaly detection. Experiment questions often explore how you would measure the impact of ranking changes or define success metrics for onboarding flows. Some candidates complete a short take-home or live case that mirrors problems found in Ads, Growth, or Safety.
Expert tip: In experiment design questions, bring up metric sensitivity, seasonality, and subreddit-specific variance. Reddit interviewers appreciate candidates who recognize that community behavior varies widely and that metrics often behave differently across subreddits.
Stage 3: Virtual onsite interviews
The virtual onsite loop includes four to five interviews that test how you solve real Reddit problems, communicate your reasoning, and work with cross-functional teams. Each round focuses on a core competency relevant to Reddit’s product surfaces.
You will typically encounter:
Product case interview
You will work through a scenario such as:
- Improving feed relevance or ranking
- Diagnosing a retention or engagement drop
- Designing metrics for onboarding or community health
Interviewers want structured thinking, clear assumptions, and the ability to tie metrics back to user experience.
Technical deep dive
This round evaluates SQL or modeling depth. Expect:
- Multi-step funnel analysis
- Anomaly detection in subreddit activity
- Identifying model drift or ranking issues
The focus is on reasoning and assumptions, not perfect syntax.
Experimentation interview
Reddit relies heavily on controlled experiments. You may:
- Design an A/B test for a high-traffic feature
- Interpret noisy or conflicting results
- Discuss potential bias across different communities
They want to see that you understand Reddit’s ecosystem variability.
Behavioral interview
This assesses collaboration and communication. You may be asked to describe:
- Influencing a roadmap decision
- Working with engineering or design
- Simplifying complex findings for non-technical teams
Expert tip: Bring two short stories: one experiment that changed a product decision and one analysis involving noisy or adversarial data. These map directly to Reddit’s real-world challenges, where community norms vary widely and signals are not always clean.
Stage 4: Team fit and hiring manager interview
This final stage assesses your collaboration style, decision making, and long-term alignment with Reddit’s data culture. Managers may ask how you prioritize conflicting metrics, influence partners, or navigate ambiguous experimentation results.
Expert tip: Share an example where you disagreed with a product or engineering and used data to shift the decision. Reddit values open debate and healthy discussion, so show that you can influence respectfully and logically.
If you want structured, one-on-one guidance tailored to Reddit’s interview style, Interview Query’s Coaching Program can help you refine your product stories, strengthen your technical thinking, and prepare confidently for any stage in Reddit’s interview cycle.
Stage 5: Hiring committee review and offer
Once your interviews are complete, Reddit compiles your performance into a single evaluation packet. The hiring committee, which usually includes senior data scientists, product leaders, and occasionally trust and safety reviewers, looks for evidence that you can make principled, data-driven decisions across Reddit’s diverse and unpredictable community ecosystem. They focus on how you handled ambiguity, whether you recognized important differences across subreddits, and how well your communication style fits Reddit’s culture of straightforward, respectful debate.
If the committee advances you, the recruiting team will walk you through level placement, equity, and initial team alignment. Since data science roles span areas like Ads, Growth, Safety, Consumer, and Marketplace, you may have a short follow-up discussion to confirm the team match. This is where Reddit ensures your strengths, such as experimentation depth, ranking analysis, or trust and safety modeling, align with the team’s upcoming priorities. Leveling is typically transparent, so expect clear explanations of scope, expectations, and ownership.
Expert tip: Ask for examples of what “successful ownership” looks like at your level during the first six months. Reddit appreciates candidates who want clear expectations and are already thinking about how to deliver impact early.
Reddit data scientist interview questions
Reddit’s interview questions reflect the realities of working with community-driven data: uneven distributions, high variance across subreddits, adversarial behavior, and the need for experimentation discipline. Below are representative questions from SQL, experimentation, product, and ML rounds paired with expert insights into what each evaluates.
SQL and analytics interview questions
Reddit’s data scientists work with billions of community interactions each month across posts, votes, comments, and subreddit sessions. Strong SQL and analytics answers demonstrate that you can reason about noisy, user-generated data, handle multi-community variance, and design metrics that hold up under real production constraints. Below are Reddit-style SQL and analytics questions with guidance on what a strong answer looks like.
1. Write a SQL query to calculate DAU by subreddit.
A solid answer starts with clarifying what “active” means at Reddit. Many teams consider a user active if they generate at least one event (view, click, vote, comment, post) in that subreddit on a given day. You would aggregate by user, subreddit, and date, using a deduped events table.
SELECT
subreddit_id,
event_date,
COUNT(DISTINCT user_id) AS dau
FROM user_events
WHERE event_date = CURRENT_DATE
GROUP BY subreddit_id, event_date;
Tip: Do not stop at the query. Explain how you’d handle bots, deleted content, or users who browse multiple subreddits. Reddit interviewers listen for your ability to manage noisy community-level signals and define DAU precisely.
2. Identify the top posts by engagement rate in the last 30 days.
Engagement rate on Reddit should consider upvotes, comments, and possibly dwell time. A strong answer discusses metric definition, filtering NSFW or quarantined subreddits, and excluding deleted or removed posts.
Tip: Mention data hygiene. Reddit expects candidates to call out vote manipulation, brigading, and bot traffic. Identifying what “true engagement” means is often more important than the SQL itself.
3. Compute retention by signup cohort.
You would group users by signup week or month, define “retained” as having at least one meaningful action, then compute retention curves.
Tip: Tie your answer to Reddit’s problem space. Retention varies widely across interest-based communities. Interviewers value candidates who account for subreddit-level variance, new-user onboarding friction, and lurking vs. active posting behavior.
4. Detect anomalies in subreddit activity.
A great answer explains whether you’re looking for drops, spikes, or distribution shifts. You might use a rolling median or z-score approach, segment by community size, and filter out events like mods closing threads or scheduled AMAs.
Tip: Bring up contextual anomalies unique to Reddit: coordinated raids, trending news cycles, or volunteer moderator changes. Showing this awareness signals real insight into Reddit’s ecosystem.
5. Find users whose posting frequency has significantly changed over time.
You can calculate a baseline posting frequency, compare it to a recent window, and identify users with large deviations.
Tip: Mention Reddit-specific use cases: Safety and Moderation teams track sudden behavioral changes to detect account takeovers, bot activation patterns, or coordinated spam. Highlight how you choose thresholds and guardrails.
Need more practice with SQL and analytics questions like these? Try a real-world data science challenge on Interview Query.
A/B testing and experimentation interview questions
Experimentation sits at the core of Reddit’s product development. Data scientists design tests for ranking changes, onboarding flows, ads placements, safety interventions, and new content formats. Strong answers show that you understand how experimentation works when user behavior varies widely across subreddits, time zones, and communities.
1. Design an experiment to test a new recommendation feed.
A strong answer begins with the objective: improving relevance or long-term engagement. Then outline the experiment unit (user or session), traffic split, guardrails, and success metrics such as dwell time, return rate, or cross-subreddit exploration. Address how variance across communities affects sample size.
Tip: Mention supply-demand imbalance. On Reddit, feed ranking shifts can affect visibility of smaller subreddits. Interviewers look for awareness of ecosystem effects, not just A/B mechanics.
2. How would you handle an experiment with mixed or conflicting signals?
Start by comparing metrics (short-term engagement vs. long-term retention), segmenting by community or cohort, and checking for user-quality differences. You might evaluate model-side metrics separately from user-facing metrics.
Tip: Bring up moderation or safety guardrails. Mixed signals often appear when a feature improves engagement but worsens content quality or increases reports. Show that you can weigh tradeoffs.
3. Define a metric to measure “user quality” across subreddits.
You could measure constructive contributions (comment-to-report ratio), session depth, dwell time, or upvote-to-downvote balance. Emphasize fairness across subreddits with different norms.
Tip: Reddit cares deeply about community nuance. A behavior that looks “low quality” in one subreddit may be normal in another. Show interviewer-level maturity by distinguishing global vs. local behavioral standards.
4. Explain how you’d test a change in ad placement without harming user experience.
Describe your experiment unit, treatment design, and guardrails such as scroll depth, time to first meaningful action, hide rate, or subreddit exit rate. Mention the need to segment by ad type, mobile vs. desktop, and cold vs. returning users.
Tip: Highlight the balancing act. Reddit wants to maximize advertiser value without increasing churn. Mention long-term retention effects.
5. How do you interpret p-values in a world with many parallel experiments?
Strong answers cover multiple-testing corrections, false discovery rate control, and test interactions across overlapping subreddits. Consider variance inflation when communities behave differently.
Tip: Connect this to Reddit’s real environment. Different teams test ranking, safety, UX, and ads changes simultaneously, often on overlapping user groups. Interviewers appreciate candidates who acknowledge practical constraints.
Want to drill deeper into A/B testing? Check out our Top 60 Statistics & A/B Testing Interview Questions for insider tips on how to answer these types of questions.
Behavioral interview questions (with sample answers)
Reddit’s behavioral interviews evaluate whether you can navigate ambiguity, collaborate across disciplines, and make thoughtful, user-centered decisions in a complex, community-driven ecosystem. Below are five verified Reddit DS behavioral questions, each paired with guidance, sample answers, and insider tips.
1. Describe a situation where a metric was misleading. What did you do?
This question tests your ability to think critically about data quality, interpret context behind metrics, and avoid overreacting to noisy community-driven signals. Reddit cares deeply about metric interpretation because seemingly positive changes can hide toxicity, brigading, or unintended moderator burden.
Sample answer:
“I once monitored a spike in comment activity that appeared positive. After segmenting by subreddit and sentiment, I realized the surge came from a contentious thread generating many reports. I introduced a ‘constructive engagement ratio’ and partnered with PMs to adjust our reporting dashboard. This gave a clearer view of community health and influenced our next iteration of moderation tooling.”
Tip: Mention subreddit-level variance. Reddit expects candidates to detect when a global metric masks community-specific problems.
2. Tell me about a project where you uncovered a user-behavior insight that changed strategy.
This evaluates whether you can connect behavioral data to product strategy and advocate for changes that meaningfully affect user experience. Reddit wants data scientists who notice nuanced patterns in how users navigate subreddits, content formats, and onboarding pathways.
Sample answer:
“In an onboarding experiment, I noticed that new users who subscribed to two niche subreddits had significantly higher long-term retention. I packaged this insight into a recommendation to introduce curated community bundles during onboarding. After testing, the personalized flow improved retention in early cohorts and became part of the broader onboarding roadmap.”
Tip: Frame insights around behaviors unique to Reddit, such as niche-subreddit discovery, comment depth, or cross-community exploration.
3. Explain a mistake you made in an analysis. What did you learn?
This question uncovers humility, willingness to correct course, and your process for building analytical safeguards. Reddit values DSs who can revise hypotheses quickly, especially when dealing with adversarial behavior or fast-moving community dynamics.
Sample answer:
“I initially attributed a drop in engagement to a new ranking model. After deeper segmentation, I realized the decline was isolated to communities undergoing moderator transitions. I corrected the analysis and added moderator-activity indicators as standard guardrails in my workflow. This prevented similar misdiagnoses and improved my communication with the community team.”
Tip: Emphasize how the mistake shaped your future analytical approach, not just what went wrong.
4. Tell me about a time you challenged a product decision using data.
This tests your ability to influence decisions thoughtfully and respectfully. Reddit is a debate-positive culture, and DSs are expected to challenge assumptions with data while remaining collaborative with PMs, engineers, and moderators.
Sample answer:
“A PM suggested removing downvotes from a sensitive content area. My analysis showed that downvotes were a helpful quality signal and prevented spam from reaching the top of feeds. I recommended testing alternative approaches instead of removing the signal entirely. After a controlled experiment, we confirmed that removing downvotes increased moderator workload, and the team pivoted to improving reporting flows instead.”
Tip: Always frame your challenge around user experience, moderator impact, and long-term trust, not just numbers.
5. How do you work with PMs, engineers, and designers when priorities conflict?
This evaluates your cross-functional leadership, negotiation skills, and clarity in setting analytical tradeoffs. Reddit teams often juggle competing needs: engineering wants reliability, PMs want fast iteration, designers want quality UX, and moderators want safety. Interviewers want to see how you build alignment and keep momentum.
Sample answer:
“During a ranking model update, engineering wanted to ship early, while design preferred more experimentation. I quantified the tradeoffs for each path, proposed a phased rollout that unblocked engineering while allowing design to iterate on UX details, and aligned both teams on shared success metrics. This balanced speed with quality and kept the roadmap intact.”
Tip: Show that your role is to anchor discussions with data, clarify constraints, and propose structured paths forward that respect each discipline’s priorities.
Machine learning and technical depth interview questions
Machine learning underpins many of Reddit’s most important systems, including ranking, spam detection, recommendations, ad quality scoring, and community safety. Strong answers show that you understand not only the ML theory but also how to apply it to Reddit’s noisy, fast-changing, community-driven environment. Reddit interviewers look for candidates who can reason about adversarial behavior, fairness across diverse subreddits, and the operational realities of building models that affect millions of daily users.
1. How does Reddit detect spam, bots, or vote manipulation?
A strong answer outlines signal categories such as behavioral patterns (posting velocity, repetition, IP clustering), graph-based anomalies (sudden cross-community vote bursts), and reputation signals (account age, prior strikes). Mention that Reddit’s anti-abuse systems often blend heuristic filters with ML classifiers trained on historical moderation data.
Tip: Bring up “contextual anomalies.” A spike in votes may be normal during an AMA or breaking-news moment but suspicious elsewhere. Reddit values candidates who understand situational nuance rather than relying only on static thresholds.
2. What metrics matter most for evaluating recommendation models on Reddit?
Start with relevance metrics such as dwell time, clickthrough rate, and save/share actions. Then add Reddit-specific considerations: cross-subreddit exploration, diversity (preventing over-concentration of similar content), comment depth, and safety or NSFW filtering. Emphasize long-term engagement instead of short-term spikes.
Tip: Mention diversity penalties or re-ranking rules. Ranking teams at Reddit actively avoid homogenizing users’ feeds and care deeply about surfacing content from smaller communities.
3. How would you monitor a model post-deployment?
Highlight monitoring feature distributions, prediction drift, subreddit-level segmentation, and outlier detection. Discuss shadow deployments, slow rollouts, and moderator feedback as qualitative guardrails. Stress that Reddit’s user behavior shifts quickly around cultural events, community drama, or moderation changes.
Tip: Include adversarial drift. Bad actors adapt quickly on Reddit, so post-deployment monitoring must detect evolving bot behavior and manipulation patterns.
4. When would you choose logistic regression versus gradient boosting for Reddit data?
Frame your answer around scale, interpretability, and interaction complexity. Logistic regression is ideal for latency-sensitive decisions such as real-time ranking or eligibility checks. Gradient boosting works better for tasks like ads quality scoring, safety classification, or predicting report likelihood, where nonlinear interactions matter.
Tip: Mention inference cost. Reddit runs billions of ranking decisions daily, so even small increases in model complexity can significantly affect system latency and compute cost.
5. How would you design features for identifying high-quality user contributions?
Talk about behavioral features (comment depth, upvote ratio, report ratio, engagement longevity), text features (toxicity scores, semantic coherence, readability), and community-context features (subreddit reputation, moderation history). High-quality contributions often combine thoughtful content with positive downstream interactions.
Tip: Emphasize subreddit context. What counts as “high quality” in r/AskHistorians differs from r/Memes. Reddit’s ML systems must respect local norms rather than enforce a single global definition.
Want to drill deeper into ML interviews? Explore hands-on ML, relevance, and safety modeling problems in the Interview Query machine learning question bank for Reddit-style questions and example answers.
How to prepare for a Reddit data scientist interview
Preparing for a Reddit data scientist interview means strengthening your technical foundation and showing that you understand how a community-driven, pseudonymous platform operates at scale. Reddit’s data teams care deeply about SQL rigor, experimentation discipline, machine learning intuition for user-generated content, and whether candidates can reason through ambiguous product decisions across tens of thousands of unique communities.
1. Master SQL for event-level, community-segmented data
Reddit tracks posts, comments, votes, awards, subscriptions, mod actions, and browsing patterns. SQL interviews often involve multi-table joins, longitudinal cohorting, retention across subs, anomaly detection, and diagnosing why different user segments behave inconsistently.
Tip: Practice writing time-windowed queries, vote-rate calculations, and community-level quality metrics that account for identity fragmentation across subs.
2. Understand experimentation across uneven, high-variance communities
Reddit’s A/B tests don’t behave cleanly because communities differ dramatically in size, culture, and noise levels. Prepare for questions on designing experiments with heterogeneous treatment effects, rollouts that avoid harming smaller subs, and guardrails that protect content quality or moderator workload.
Tip: Be comfortable explaining how you’d interpret an experiment that succeeds on r/technology but shows contradictory results on niche subreddits.
3. Build intuition for ranking, relevance, and safety models
Reddit’s ML stack must optimize for freshness, diversity, community norms, and platform trust. You may be asked about feature engineering for ranking, spam or abuse detection, repost identification, or thread relevancy models. Strong candidates can articulate tradeoffs between engagement and healthy discourse, and how to detect when a model drifts toward over-representing large subs.
Tip: Practice explaining a high-level pipeline for detecting adversarial behavior (brigading, bots, coordinated voting) and how you’d evaluate model fairness across communities.
4. Strengthen product sense for community health and discovery
Reddit’s product interviews focus on how users find communities, how content surfaces in Home and Popular feeds, and how conversations evolve. Prepare to define metrics like safe engagement, comment depth, subscription conversion, and cross-subreddit diversity. Interviewers look for candidates who understand discovery friction, moderation capacity, and community-level incentives.
Tip: Analyze a few subreddits. Look for early-user friction points, moderation dynamics, and signals that differentiate high-quality posts.
5. Craft behavioral stories that show ownership under ambiguity
Reddit values clarity, bias for action, and cross-functional coordination. Come with STAR stories showing how you resolved conflicting signals, built consensus, influenced product direction, handled data ambiguity, or worked with constraints like latency, safety risk, or incomplete metrics.
Tip: Highlight stories where you balanced user experience with responsible outcomes. You can also bring an example where you aligned stakeholders around a safety-first decision, showing how you handle the types of tradeoffs Reddit faces across communities. For practice, use Interview Query’s mock interviews to simulate real cross-functional data science conversations.
Need a deeper dive into behavioral interviews? In this video, Interview Query co-founder and data scientist Jay Feng offers practical guidance on how to structure and communicate your leadership and behavioral stories during interviews — exactly what Reddit interviewers look for when probing decision-making under ambiguity and cross-functional collaboration.
By watching the video, you will learn how to emphasize collaboration, stakeholder alignment, and how you handled trade-offs or setbacks. These are critical when explaining ambiguous product or safety-driven decisions.
6. Prepare for trust & safety-driven analytical tradeoffs
Even in product-facing roles, data scientists at Reddit frequently consider safety implications. Expect questions about reducing harmful content exposure, tuning filtering systems, identifying brigading or misinformation, or minimizing moderator burden. Good answers show empathy for users, moderators, and product teams.
Tip: Practice frameworks for evaluating safety interventions such as precision/recall tradeoffs, automation risks, and how to quantify harmful exposure without over-filtering.
7. Study Reddit’s ads, relevance, and recommendation systems
Teams in Ads, Growth, and Relevance test whether you understand dwell time, feed diversity, quality weighting, and the risks of over-favoring large subreddits. You may be asked how ranking changes influence trust, spam exposure, or community health at scale.
Tip: Prepare to explain how you’d diagnose ranking regressions and protect smaller or niche subreddits from algorithmic overshadowing.
8. Prepare one deep, end-to-end project walkthrough
Reddit’s data is noisy, unstructured, and adversarial. Choose a project that involved imperfect logs, shifting requirements, stakeholder disagreements, or ambiguous signals. Interviewers want to hear how you cleaned the data, made principled assumptions, communicated tradeoffs, and delivered measurable impact.
Tip: Prepare a short 90-second pitch and a deeper 5-minute version so you can adapt based on the interviewer’s direction. Examples of data science project interview questions can be found here.
Average Reddit data scientist salary
Reddit data scientists earn competitive compensation across levels, influenced by scope, team, and location. According to Levels.fyi, total annual compensation in the United States generally ranges from ~$175K at IC1 to $350K+ at senior and staff levels, with a nationwide median around $230K–$260K. Stock grants represent a meaningful portion of total compensation, especially for senior roles and teams.
| Level | Total/Year | Base/Year | Stock/Year | Bonus/Year |
|---|---|---|---|---|
| IC1 – Data Scientist I | ~$177K | ~$134K | ~$36K | ~$7K |
| IC3 – Data Scientist III | ~$206K | ~$156K | ~$44K | ~$6K |
| IC4 – Senior Data Scientist | ~$268K | ~$178K | ~$78K | ~$12K |
| IC5 – Staff/Lead Data Scientist | $330K–$360K+ | ~$205K | $110K–$140K | $20K+ |
Reddit’s compensation packages usually include four-year equity grants alongside base salary and performance bonuses. The value of these stock grants depends on your level and team, and they often represent a meaningful part of your total package. You’ll also find benefits like wellness stipends, learning budgets, flexible work options and access to office hubs in major U.S. cities. Keeping all of these pieces in mind makes it easier to understand the full picture of an offer and how it might grow over time.
Average Base Salary
Average Total Compensation
Location-based salary bands for Reddit data scientists
Reddit uses location-indexed compensation bands, meaning total pay varies depending on whether you’re based in a high-cost metro (e.g., San Francisco Bay Area), a mid-cost tech hub (e.g., Seattle, Austin, Denver), or a fully remote region. While Reddit offers flexible and hybrid options, compensation is calibrated to market cost-of-living and talent competition in each location. Below is a representative snapshot of how compensation typically adjusts across regions for data scientists.
| Region | Typical Total Compensation | Notes |
|---|---|---|
| Bay Area/SF Headquarters | $240K–$360K+ | Highest comp band; includes roles on Relevance, Ads, Core Product, and Safety. Equity refreshes tend to be larger here. |
| Seattle/New York City | $220K–$320K | Slightly below SF bands but competitive, especially for ML, Ad Quality, and Marketplace roles. |
| Austin/Denver/Chicago | $190K–$260K | Mid-market hubs with strong demand; often attract candidates who want hybrid flexibility with lower cost of living. |
| Fully Remote (U.S. nationwide) | $170K–$240K | Compensation typically tied to regional cost bands; equity remains consistent but base often varies. |
| International (EMEA/APAC) | Varies widely | Comp structures reflect local labor markets; many roles outside the U.S. focus on analytics, trust/safety, or platform tooling. |
Reddit uses a hybrid compensation model where base salary adjusts by market while equity remains relatively consistent across locations. Remote roles are fully supported, but pay is calibrated to the cost of living in your home region.
Understanding how these location-based bands work helps you benchmark offers accurately, negotiate with confidence, and weigh tradeoffs between cash, equity, and long-term career growth, especially if you’re considering roles on high-impact teams like Relevance, Ads, or Safety, where compensation may trend toward the upper ranges regardless of geography.
FAQs
How many rounds are in Reddit’s data scientist interview process?
Most candidates complete a recruiter screen, one or two technical assessments, and four to five virtual onsite interviews covering SQL, statistics, experimentation, product reasoning, and behavioral conversations. Some teams add a modeling or case-study round depending on scope.
Does Reddit include a take-home challenge, and what is its format?
Some teams use a short, focused take-home exercise that evaluates practical skills such as retention analysis, metric design, or experiment interpretation. These assignments are typically designed to be completed in two to three hours.
What data tools does Reddit use internally?
Reddit employs SQL, Python, Spark, Airflow, and modern data warehouses. Many teams also rely on internal relevance tooling, large-scale event pipelines, and content-quality classifiers for ranking and safety use cases.
How technical is the hiring manager round?
The hiring manager conversation blends technical and strategic depth. Expect questions about experiment design, metric choices, past project decisions, and how you collaborate with engineering, product, design, and moderators.
Does Reddit emphasize SQL or Python more in interviews?
SQL is emphasized more consistently because most analysis, experimentation, and product work depends on it. Python appears in certain roles, especially those involving modeling, relevance ranking, or safety classification.
How do Reddit’s data science roles differ across teams?
Core Product focuses on engagement and feed relevance, Ads centers on quality scoring and auction performance, and Safety works on abuse detection, community health, and moderator support. While all teams value experimentation and communication, each team prioritizes different metrics and modeling approaches.
Are Reddit data science roles remote-friendly?
Yes, many roles are open to remote candidates within the United States. Compensation aligns with regional bands, and some teams also offer hybrid access to hubs in cities like San Francisco and New York.
How important is A/B testing experience at Reddit?
Experimentation is central to most Reddit teams, especially Relevance, Growth, and Ads. Candidates should be comfortable framing hypotheses, choosing guardrails, interpreting noisy results, and accounting for wide variance across subreddits.
What are common mistakes candidates make in Reddit interviews?
Many candidates overlook subreddit-level differences, rely on generic metrics, or fail to consider community or moderator impacts. Interviewers notice when answers ignore tradeoffs between engagement, safety, and long-term user trust.
How long does the overall process typically take?
Most candidates progress through the process in three to six weeks. Timelines vary based on team scheduling, availability for onsite rounds, and whether a take-home challenge is included.
What qualities make a standout Reddit data science candidate?
Reddit looks for analytical thinkers who communicate clearly, handle ambiguity well, and understand how community behavior shapes product outcomes. Curiosity, empathy for users and moderators, and a habit of grounding decisions in evidence stand out strongly.
Conclusion: Stand out in the Reddit data scientist interview
Succeeding in Reddit’s data scientist interview means showing that you understand the complexity of a community-driven platform and can turn noisy, multi-subreddit signals into clear, actionable insight. Interviewers look for candidates who can design robust experiments, interpret divergent community behaviors, and communicate tradeoffs that balance engagement, safety, and long-term user trust.
Interview Query can help in your upcoming interviews with its question bank on most asked data science interview questions. Try out the mock interview tool and the data science learning path to build confidence for every stage of the Reddit interview process. Start your prep journey today!
Reddit, Inc. Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||||||||||||||||||||||||||||||
We’re given three tables representing a forum of users and their comments on posts. Write a query to get the top three users that got the most upvotes on their comments written in 2020. Note: Do not count deleted comments and upvotes by users on their own comments Example: Input:
Output:
| ||||||||||||||||||||||||||||||||||||||||||
Data Structures & Algorithms | Easy | |||||||||||||||||||||||||||||||||||||||||
SQL | Medium | |||||||||||||||||||||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences