
Pure Storage Data Scientist Interview Guide (2025): Process, Questions & Salary Insights


Introduction
Preparing for a Pure Storage data scientist interview? You’re aiming at one of the few roles in tech where machine learning directly shapes the reliability and performance of enterprise-scale flash systems. Data scientists at Pure Storage earn highly competitive salaries and work on problems at petabyte scale, making the role both rare and impactful.
In this guide, you’ll learn exactly what to expect in the Pure Storage data scientist interview process: from online assessments to system design and behavioral rounds. We’ll break down day-to-day responsibilities, role culture, and common interview questions, along with preparation strategies that will help you stand out. Whether you’re a new grad or an experienced professional, this roadmap will give you the clarity and tools to approach each round with confidence.
Role Overview & Culture
As a Pure Storage data scientist, you’ll be at the intersection of cutting-edge flash storage innovation and real-world machine learning applications. Your day-to-day will span building robust analytics pipelines, prototyping models to predict system behavior, and collaborating closely with FlashBlade product teams to translate raw telemetry into actionable product intelligence. You’ll work alongside the Pure Storage data team, known for its deep technical expertise and collaborative spirit.
What sets Pure Storage apart is its unwavering commitment to the customer-first value. Your models will directly enhance user experience across petabyte-scale deployments. With an agile development cycle and a culture that champions bottom-up experimentation, you’ll have autonomy to explore ideas and rapidly iterate, backed by strong engineering support.
Why This Role at Pure Storage?
Becoming a data scientist at Pure Storage means working on challenges that only a handful of companies in the world face, like optimizing reliability and performance at petabyte scale. The opportunity is both technical and strategic: your models influence how mission-critical storage systems behave in real time for some of the world’s largest enterprises. Compensation is highly competitive.
What makes the role stand out even more is the growth path. It emphasizes strong individual contributors, giving you the chance to move into staff-level or leadership positions without leaving hands-on work behind. If you’re looking for a role that combines scale, autonomy, and a clear technical career trajectory, Pure Storage offers a rare mix.
Now, let’s explore the Pure Storage interview process step by step.
What Is the Interview Process Like for a Data Scientist Role at Pure Storage?
The Pure Storage data scientist interview process is designed to assess both your technical depth and your ability to apply machine learning to real product challenges at scale. Here’s what to expect:
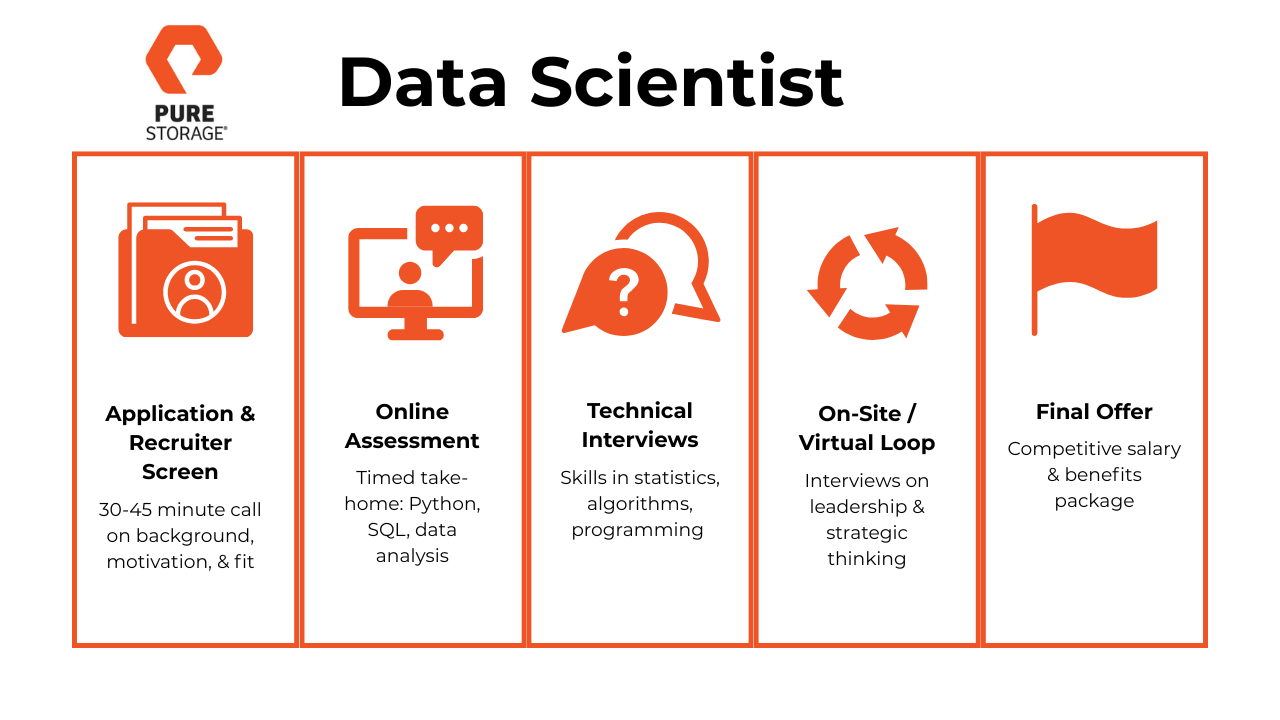
Application & Recruiter Screen
The process begins with a 30–45 minute conversation with a recruiter. This call typically covers your background, motivation for applying, and alignment with the data scientist role at Pure Storage. It’s also your chance to clarify role expectations and showcase enthusiasm for the company’s culture and values.
Tip: Prepare a 60–90 second “career story” that ties your past experience to why you want to solve large-scale data challenges at Pure Storage.
Online Assessment (OA)
Next is a timed take-home assessment focused on Python, SQL, and exploratory data analysis. You’ll usually face 2–3 problems in 60–75 minutes, testing your ability to write clean code, query datasets, and interpret results under time pressure. Scores are automated but often reviewed manually if you are close to the cutoff.
Tip: Practice solving LeetCode-style SQL and Python problems under timed conditions, and narrate your steps so you can later reuse the same clarity in technical interviews. You can practice these questions on Interview Query dashboard.
Technical Interviews
This interview focuses on your analytical skills, including your proficiency in statistics, algorithms, and programming languages such as Python or SQL. Expect to discuss your experience with data analysis, data modeling, and any relevant projects that demonstrate your ability to extract insights from complex datasets.
Tip: Be ready to start with a brute-force solution and then refine to an optimized approach. Interviewers value your improvement process as much as your final answer.
On-site or Virtual Loop
The final interview usually involves discussions with senior leadership or executives. This round focuses on strategic thinking and how your skills align with the company’s long-term goals. You may be asked about your vision for data science within the organization and how you can drive business value through data-driven insights.
Tip: Prepare 1–2 STAR stories that highlight leadership and strategic impact, not just technical depth. This shows you can influence both systems and outcomes.
Offer
Once all rounds are complete, the hiring committee typically responds within a week. Offers usually include a competitive base salary, bonus potential, and equity grants that scale with seniority. Recruiters often discuss next steps, relocation (if relevant), and start date flexibility.
Behind the Scenes
Feedback is collected after each round and reviewed by a hiring committee composed of senior data scientists and cross-functional leaders. Pure’s process values signal alignment over pedigree, and timely updates are a priority. Most candidates are notified of outcomes within 5–7 business days.
Differences by Level
For IC-level candidates, the focus is on technical execution, clarity of thought, and coding ability. Senior and Lead candidates are expected to demonstrate strategic thinking, influence over product direction, and the ability to mentor others and drive cross-team initiatives.
After learning about the interview process, let’s dive into Pure Storage Data Scientist interview questions.
Challenge
Check your skills...
How prepared are you for working as a Data Scientist at Pure Storage?
What Questions Are Asked in a Pure Storage Data Scientist Interview?
Coding/Technical Questions
Expect a mix of Python and SQL questions that assess your ability to manipulate data, perform aggregations, and solve analytical problems under real-world constraints. These coding questions for Pure Storage data science interviews emphasize both logic and efficiency.
Group a list of sequential timestamps into weekly lists starting from the first timestamp
Approach this with date arithmetic and slicing in Python. You want to iterate through the list while maintaining buckets that restart every 7 days. Pay attention to edge cases like timezone-aware timestamps or gaps. This is a great example of coding questions for Pure Storage data science interviews that test data manipulation skills.
Tip: Normalize all timestamps to the same timezone before grouping; DST and tz offsets can silently break boundaries.
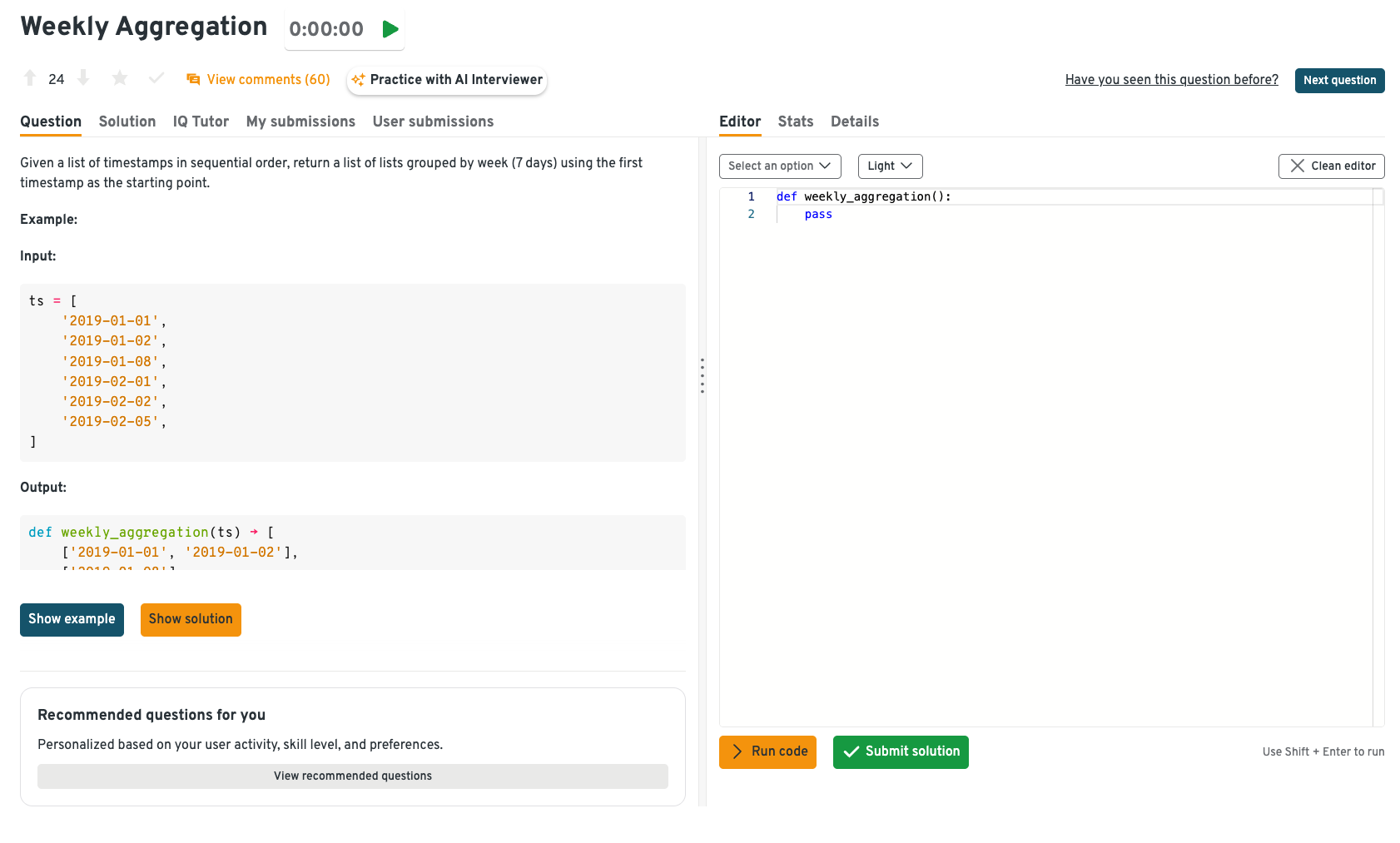
On the Interview Query dashboard, you don’t just get the problem prompt; you also see hints, detailed walkthroughs, and solution breakdowns. For a question like weekly aggregation, the platform guides you from a naive loop implementation to a clean, production-ready Python solution, pointing out pitfalls like timezone handling and edge gaps. This layered learning approach ensures you’re not just solving the problem once but internalizing the pattern for real-world interviews.
Write a function to return the top N frequent words in a corpus
Use a dictionary or
collections.Counterto track frequencies. Sort the frequencies in descending order and return the top N keys. Watch out for stop words or ties. These types of Python prompts test your ability to structure data summaries efficiently.Tip: Define tie-breaking up front (e.g., lexicographic after frequency) if you need deterministic output.
Select the top 3 departments with at least ten employees by average salary
This query calculates both the proportion of employees earning more than $100K and the department’s employee count. It uses a CASE WHEN expression inside AVG() to compute the percentage of employees above the threshold, while COUNT(*) tallies total headcount. The HAVING clause ensures that only departments with at least 10 employees are considered, and the final ORDER BY ranks departments by the highest proportion of high earners.
SELECT AVG(CASE WHEN salary > 100000
THEN 1 ELSE 0 END) AS percentage_over_100k,
d.name AS department_name,
COUNT(*) AS number_of_employees
FROM departments AS d
LEFT JOIN employees AS e
ON d.id = e.department_id
GROUP BY d.name
HAVING COUNT(*) >= 10
ORDER BY 1 DESC
LIMIT 3;
Tip: When mixing aggregates, clearly label calculated fields like percentage_over_100k to make results easy to interpret and avoid confusion in review. Review CASE WHEN function to make sure you avoid any common mistakes.
4 . Count users who made additional purchases after an initial upsell
This query identifies customers who transacted on more than one distinct date, signaling at least one upsell followed by an additional purchase. The inner query groups transactions by user_id and filters with HAVING COUNT(DISTINCT DATE(created_at)) > 1 to ensure multiple purchase days. The outer query simply counts how many unique users meet this condition, returning the number of upsold customers.
SELECT COUNT(*) AS num_of_upsold_customers
FROM (
SELECT user_id
FROM transactions
GROUP BY user_id
HAVING COUNT(DISTINCT DATE(created_at)) > 1
) AS t;
Tip: Always clarify the upsell definition (same day vs. different days). Using COUNT(DISTINCT DATE(created_at)) ensures purchases are spread across multiple days, reducing false positives from same-day repeats.
Product/Experiment Design Questions
This section focuses on A/B test design, experiment validity, and product metric interpretation. You’ll need to demonstrate statistical rigor and business intuition in assessing causal impact and defining success. You can learn more about product interview questions for data scientists on Interview Query.
Design an A/B test to evaluate changing a button’s color
Define the hypothesis clearly and ensure randomization. Choose a primary metric (e.g., click-through rate) and determine sample size. Consider how to handle novelty effects or overlapping users. This is a classic Pure Storage data scientist interview question to assess experimental intuition.
Tip: Always explain how you’d monitor the test during rollout. Early spikes could reflect novelty bias, not long-term behavior.
Assess the validity of a .04 p-value in an AB test after 3 metrics were evaluated
This challenges your understanding of multiple comparisons and false positives. Consider the Bonferroni correction or false discovery rate. Discuss whether the metric was pre-specified. This question probes statistical rigor, a key skill for experiment-heavy roles.
Tip: Show that you understand p-values in context. Don’t just recite corrections; tie them to decision-making and the risk of shipping a false positive.
Identify reasons and metrics for decreasing average comment counts
Break the problem into engagement funnel stages (e.g., views → likes → comments). Suggest possible root causes like UX changes or algorithm shifts. Recommend diagnostic metrics. This tests your ability to infer hypotheses from user behavior data.
Describe how to measure the success of Instagram TV
Propose primary metrics like watch time, retention, or creator participation. Recommend segmentation and baselining vs other features. Tie metrics to business outcomes. Product metrics questions like this assess your metric design under ambiguity.
Tip: Frame your answer with both what happened (metrics) and why (hypotheses), showing you can separate observation from root-cause analysis.
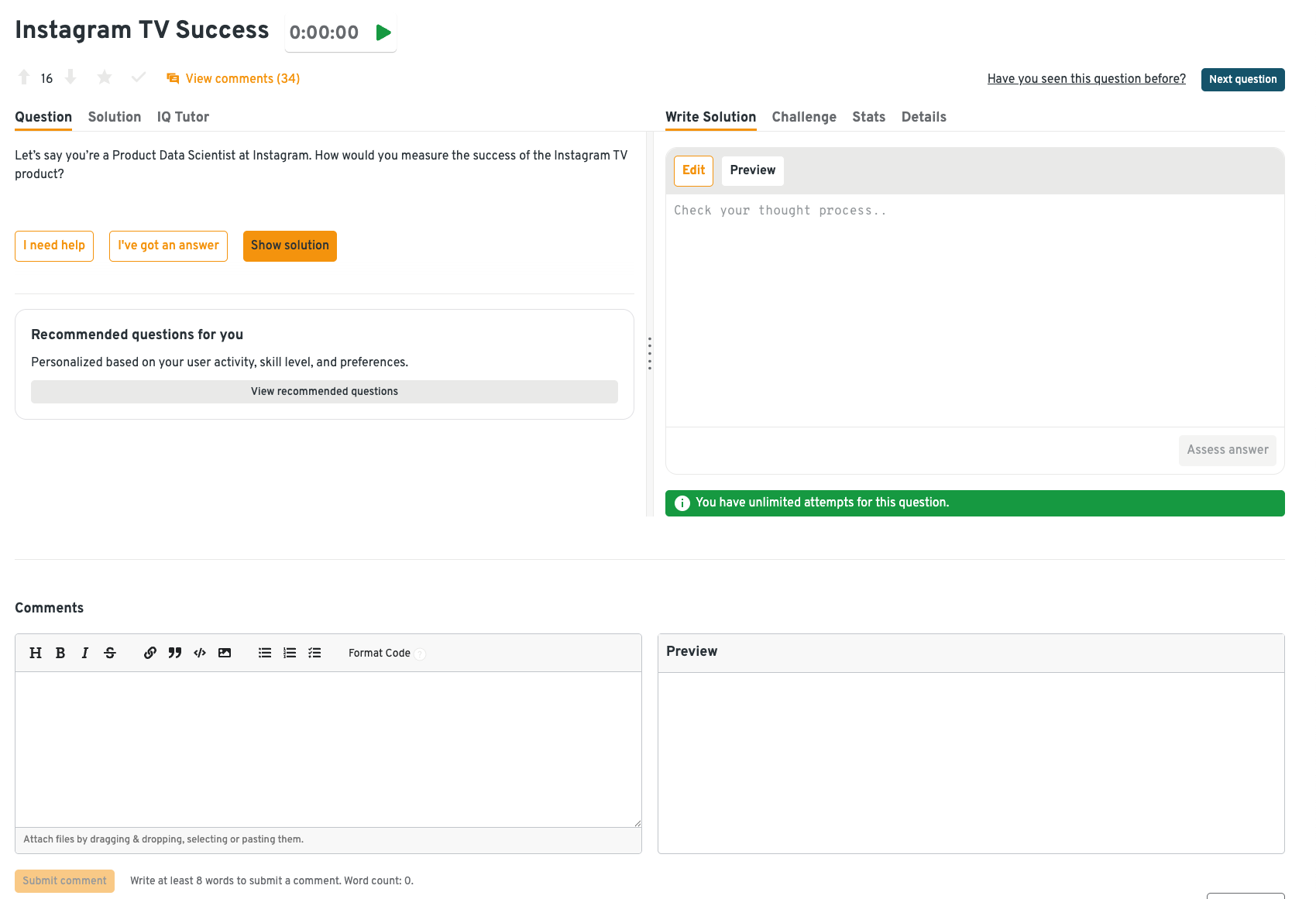
On the Interview Query dashboard, each product design question, like this, comes with step-by-step frameworks and example answers. For “Instagram TV success,” you’ll see how to prioritize leading indicators such as creator adoption and repeat watch sessions, then balance them with lagging business metrics like ad revenue and retention. Learners benefit from seeing how real data scientists structure ambiguous product questions, so they can mirror this process in live interviews.
Identify potential flaws in VP’s assumption that insurance leads are bad based on low conversion
Probe whether there’s enough context behind the assumption. Consider external factors or quality over quantity metrics. Recommend segmenting lead sources or surveying. These questions test your challenge-driven thinking and stakeholder alignment.
At first glance, a low conversion rate might suggest that insurance leads are “bad,” but this conclusion can be misleading without context. Conversion alone doesn’t capture the full value of a lead. Some leads may convert less frequently but yield higher lifetime value (LTV), better retention, or higher margins. For example, a VP might dismiss insurance leads if they convert at 2% compared to 8% for another channel, but if those insurance customers stay 3x longer or purchase larger packages, they may still be more profitable overall.
Other flaws include seasonality (leads may convert more slowly at certain times of year), funnel leakage (perhaps the landing page is poorly optimized), or misattribution (insurance leads may actually convert later but through a different channel, like phone sales rather than online). A stronger approach would be to segment leads by source, compare downstream metrics like retention or LTV, and run surveys to understand intent before dismissing them.
Tip: Always challenge assumptions with additional metrics. Pair conversion with quality (LTV, repeat purchase, retention) and with context (channel performance, funnel stage). This shows you think like a business partner, not just an analyst.
Behavioral & Culture‑Fit Questions
Pure Storage values ownership, customer obsession, and collaborative problem-solving. These behavioral questions reveal how you align with the company’s culture and how you’ve navigated challenges in past data projects. You can find more behavioral interview questions on Interview Query.
Tell me about a time you had to advocate for a customer’s needs in a data-driven project.
Discuss how you gathered user feedback and translated it into an analysis. Highlight how you pushed for prioritizing their needs in roadmap discussions. Include any measurable impact or outcomes. This aligns with Pure Storage’s customer obsession principle.
Example: In one project, half the team used different linting rules. I proposed a shared config, documented it, and reduced review conflicts by 40%.
Tip: Frame yourself as a collaborator, not an enforcer. Emphasize team alignment over individual preference.
Describe a time when you took ownership of a project without being asked.
Share how you noticed a gap or opportunity and acted independently. Walk through how you scoped, executed, and delivered results. Include how stakeholders responded or adopted your solution. This signals initiative and bias for action.
Example: I rewrote a SQL pipeline in Spark despite longer dev time; it cut job runtime from 8 hours to 50 minutes.
Tip: Always tie trade-offs back to business impact. Pure Storage values results over theoretical optimizations.
How do you handle feedback, especially when it conflicts with your original analysis?
Emphasize your openness to alternate views and data points. Show how you validate your assumptions and integrate new insights. Use a real example of adjusting based on feedback. This tests humility and collaboration under challenge.
Example: While building an API, I hosted weekly design reviews and wrote clear docs, which helped downstream teams integrate 2 weeks faster.
Tip: Stress feedback and documentation. Both are tangible signals of ownership.
Tell me about a time you influenced someone without formal authority.
Pure Storage values engineers who can guide decisions by building trust and presenting clear evidence, rather than relying on titles. The goal is to demonstrate that you can work cross-functionally, align stakeholders, and create impact even when you’re not the decision-maker. Strong answers should show how you used data, prototypes, or persuasive communication to bring others on board. Highlight both the collaborative process and the measurable outcome.
Example: During a cross-team project, I created a dashboard that clarified KPIs. The product team adopted it, improving approval rates by 5%.
Tip: Emphasize how you combined empathy with evidence. Balancing interpersonal skills and data-driven reasoning is what makes your influence credible.
Give an example of when you had to make a decision under ambiguity.
Interviewers want to see that you can move forward without perfect information, while still making thoughtful, risk-aware choices. At Pure, projects often run on tight timelines, so waiting for complete data can delay delivery. Instead, show how you identified what information was available, made assumptions where necessary, and communicated risks transparently. Focus on structured reasoning and how you adapted as more information became available.
Example: On a feature rollout, we lacked complete performance benchmarks. I ran small-scale tests, flagged risks, and launched iteratively, which helped us deliver on time.
Tip: Stress your ability to take calculated risks and iterate. Pure Storage rewards pragmatism combined with accountability.
Share a situation where you taught yourself a new tool to unblock a team.
This question evaluates curiosity, initiative, and your willingness to take ownership of problems. Instead of waiting for outside expertise, strong candidates demonstrate they can quickly learn new technologies to keep projects moving. Your answer should show how you identified the blocker, invested in self-learning, and translated that knowledge into a solution for your team. The story should underline both technical growth and collaborative impact.
Example: Our analysis stalled on big JSON logs; I self-learned PySpark over a weekend and built a pipeline, cutting analysis time from days to hours.
Tip: Show eagerness to self-learn and focus on impact. They looks for engineers who remove roadblocks proactively.
Describe a time when you challenged an assumption from leadership.
Pure values engineers who think critically but also communicate with respect and diplomacy. Challenging leadership requires balancing assertiveness with data and framing your input as a refinement of strategy, not an attack. The best answers highlight how you uncovered deeper insights or alternative perspectives and presented them constructively. Show that your challenge led to better business outcomes and stronger trust with leadership.
Example: When a VP assumed low-converting leads were bad, I segmented by LTV and showed those leads had 3x higher lifetime value. The VP adjusted the strategy accordingly.
Tip: Be diplomatic: frame challenges as clarifying or expanding the picture with more data, not contradicting authority.
How to Prepare for a Data Scientist Role at Pure Storage
Preparing for a data scientist role at Pure Storage means aligning your technical skills with the company’s unique product focus and fast-paced experimentation culture. Here’s how to structure your prep to stand out across each stage of the interview process.
Map the Job Description to Core Skills
Break down the role into core domains: model development, analytical storytelling, and product experimentation. Use the job post as a blueprint to guide your prep and project selection.
Tip: Pull three bullet points from the JD and build a prep plan where each one maps to a specific skill (e.g., “SQL queries → window functions practice,” “telemetry modeling → anomaly detection project”).
Rebuild a Flash Storage Analytics Case Study
Pure’s data science work often centers on storage telemetry. Try recreating a simplified version of a flash performance monitoring tool or anomaly detection pipeline to showcase domain relevance in your portfolio. A project like this demonstrates that you understand Pure’s product space and can translate raw data into actionable insights.
Tip: Don’t just show code. Visualize latency spikes or anomaly clusters in a dashboard; Pure’s engineers value insights they can interpret at a glance.
Drill 30-Minute SQL + Python Challenges
Expect time-constrained live-coding rounds. Practice structured problems that involve joins, window functions, and numpy/pandas transformations. Use the “think out loud” approach: walk through assumptions and logic as you code so interviewers follow your reasoning.
Tip: Simulate pressure. Set a 30-minute timer, solve one SQL and one Python problem back-to-back, then review your clarity as if an interviewer were listening. You can practice these questions on Interview Query dashboard.
Refresh Causal Inference Techniques
You’ll likely be tested on how you evaluate the causal impact of product launches or infrastructure changes when true A/B testing isn’t feasible. Senior candidates in particular should be fluent in quasi-experimental methods like Difference-in-Differences (DID), Regression Discontinuity (RDD), and Instrumental Variables. The key is showing you can frame the business context, state assumptions, and validate robustness with sensitivity checks.
Sample questions you might encounter:
- Pure Storage introduces a new storage compression feature in some regions but not others. How would you apply DID to estimate its effect on adoption rates?
- If feature eligibility is determined by a usage threshold (e.g., more than 10 TB storage), how would you set up a regression discontinuity design?
- What assumptions underlie DID, and how would you test whether parallel trends hold using historical Pure Storage customer data?
- How would you explain to a product manager why quasi-experimental results may differ from results obtained via randomized trials?
Tip: Practice explaining these methods in plain English to a non-technical product manager. It proves you understand the trade-offs, not just the math.
Book a Mock Interview with an Ex-Pure Storage Engineer
Real feedback from someone who’s been through the process can level up your prep. Practice using the “brute-force then optimize” strategy to show depth and iterative problem-solving under pressure.
Tip: Use Interview Query mock interviews to get structured feedback on SQL, coding, and experiment design from people who know Pure’s process.
FAQs
What Is the Average Salary for a Data Scientist at Pure Storage?
Pure Storage data scientists earn $167K -$246K per year, including 75.3% of base pay, 7.3% of bonus, and 17.4% of stock.
Are there job postings for Pure Storage data scientist roles on Interview Query?
Yes! Check out our Jobs Board to see current openings, or sign up for email alerts to get notified when new roles match your interests and experience.
Is SQL asked in a data science interview?
Yes. SQL is almost always part of a data science interview, including at Pure Storage. It’s the primary tool for extracting and aggregating data, and interviewers use SQL questions to test both logic and efficiency. Expect problems involving joins, window functions, subqueries, and aggregation.
How to handle NULL values in SQL?
NULLs represent missing or undefined data, and they can break calculations if not handled explicitly. Common strategies include using COALESCE() to replace NULLs with a default, filtering them out with WHERE column IS NOT NULL, or accounting for them in aggregations. For example, AVG(column) ignores NULLs, but COUNT(column) also skips them. So always confirm behavior before reporting results.
What are common mistakes in a data science interview?
Candidates often make three types of mistakes: jumping straight into code without clarifying requirements, failing to think out loud so interviewers can follow their logic, and overcomplicating solutions when a simple baseline would work. Another common slip is not connecting technical answers back to business impact. For SQL preparation, read this article from Interview Query to learn about common SQL interview mistakes and how to avoid them.
How do you introduce yourself during a Pure Storage data science interview?
Your introduction should be concise, structured, and tailored to Pure. Start with your current role or studies, then highlight relevant technical strengths (Python, SQL, machine learning, experimentation). Connect those skills to Pure’s context, like handling large-scale telemetry data or designing experiments for infrastructure products. End with what excites you about the role.
Example: “I’m a data scientist with experience building anomaly detection pipelines and designing A/B tests. I enjoy working on large-scale systems, which is why I’m excited about Pure’s mission of optimizing storage performance at petabyte scale.”
How do you explain data science projects in an interview?
Structure your explanation with problem → approach → tools → impact. Start with the business or technical problem, then describe your methodology and tools (Python, SQL, Spark, etc.). Share results in concrete terms (accuracy, runtime, revenue uplift) and finish with a reflection on what you learned or would improve. Pure Storage interviewers care about both technical execution and how your work drives outcomes.
Conclusion
Whether you’re exploring the Pure Storage data scientist interview process for the first time or preparing for your final round, this guide offers the clarity and context to navigate each step with confidence. From role expectations to salary insights, you’ve now got a solid foundation to move forward.
For more details across roles, check out our Pure Storage Interview Questions & Process, or dive into the Pure Storage Software Engineer interview guide.
Need more preparation? Book a mock interview to get real-time feedback.
Pure Storage Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Medium | |
Write a Python function called Note: An increasing subsequence is a subset of a list where the elements are in strictly increasing order. The subsequence does not have to be contiguous or unique. Example:Input: Output: Explanation: The longest increasing subsequence is | ||
Data Structures & Algorithms | Easy | |
SQL | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences