
NVIDIA Machine Learning Engineer Interview Guide (2025)


Introduction
As a NVIDIA machine learning engineer, you’ll work at the forefront of innovation in AI, designing scalable ML pipelines and accelerating model performance through GPU-optimized training frameworks. Day-to-day, that means hands-on ownership of MLOps infrastructure, building tools that support everything from generative AI to autonomous driving. You’ll collaborate with researchers, product teams, and hardware engineers to deploy robust ML models in high-performance, production-grade environments. NVIDIA’s culture values rapid iteration, low ego, and technical excellence—decisions are made bottom-up, and good ideas can come from anywhere.
NVIDIA’s impact spans industries: powering breakthroughs in robotics, leading the charge in generative AI SDKs, and enabling mission-critical perception systems in self-driving cars. As a machine learning engineer at NVIDIA, you’ll not only shape the future of AI applications but also benefit from competitive compensation packages (including generous RSUs) and long-term growth across hardware, research, and software orgs. Whether you’re drawn to deep tech or productized ML, this is a chance to work with leaders in the space. In the next sections, we’ll walk through the NVIDIA machine learning engineer interview process, from recruiter screens to technical deep dives.
What Is the Interview Process Like for a Machine Learning Engineer Role at NVIDIA?
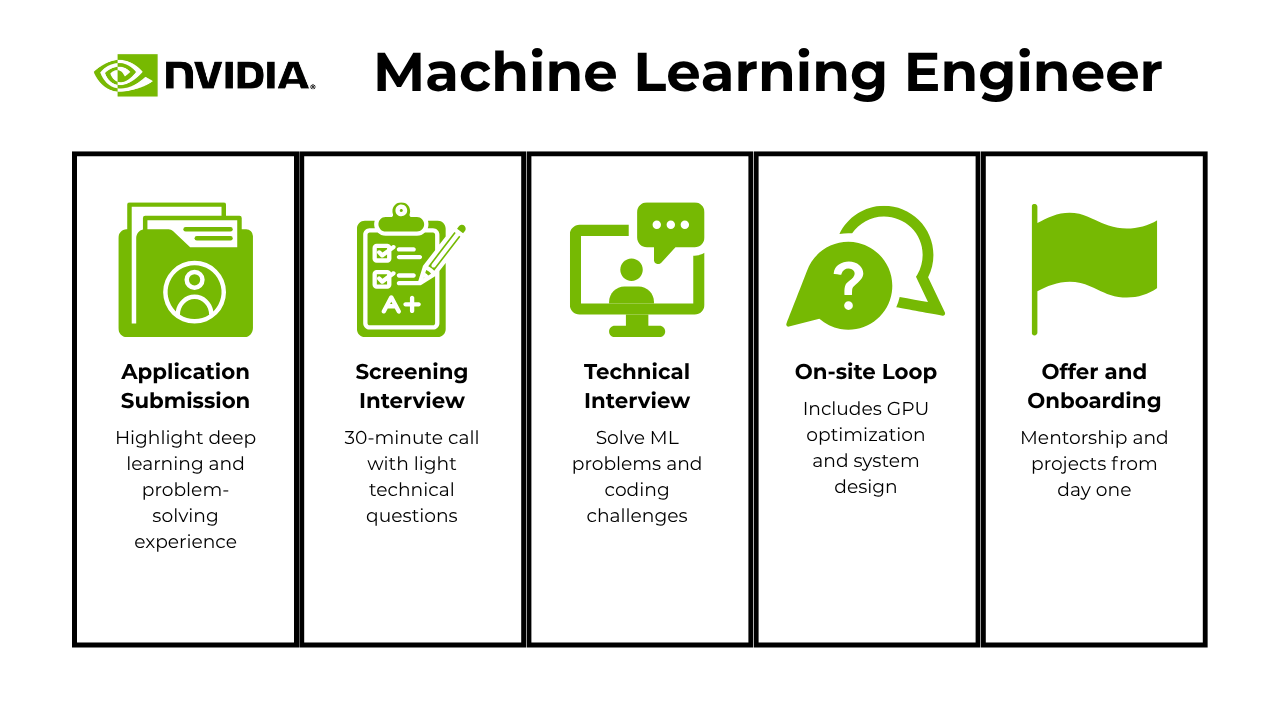
Overview of the Interview Process
The NVIDIA machine learning engineer interview is designed to assess both technical depth and your ability to thrive in a high-performance, collaborative environment. If you’re preparing to interview a machine learning developer at NVIDIA, here’s how the process typically unfolds:
Application Submission
You’ll apply through NVIDIA’s career portal or be encouraged by a hiring manager to submit your resume. Make sure your application highlights experience in algorithm development, deep learning frameworks, and complex problem-solving in artificial intelligence. Tailor your resume and cover letter to reflect your technical strengths and passion for machine learning.
Screening Interview
Your first interaction is typically a 30-minute conversation with a recruiter. This round covers your background, experience, and technical competencies. Expect a mix of light technical and behavioral questions designed to assess your fit for the role and interest in NVIDIA’s mission.
Technical Interview
If you pass the screen, you’ll enter one or more technical interviews led by senior engineers. These sessions dive into algorithmic complexity, ML model optimization, and coding challenges. You may also receive a take-home assignment that mirrors real-world tasks handled by ML engineers. Show your fluency with ML tools and frameworks as you tackle domain-specific problems.
On-site Loop
The final stage is a series of virtual or in-person interviews with peers, managers, and technical stakeholders. As a NVIDIA ML engineer, you’ll be evaluated on both your technical depth and ability to thrive in a fast-paced, innovative setting. These rounds may include deep dives into GPU optimization, model scaling, or system architecture.
Offer and Onboarding
If successful, you’ll receive an offer to join NVIDIA as a machine learning engineer. This reflects your technical excellence and potential to innovate within one of the world’s leading AI companies. Once accepted, onboarding will equip you with the tools, mentorship, and projects needed to hit the ground running.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Nvidia?
What Questions Are Asked in a NVIDIA Machine Learning Engineer Interview?
If you’re preparing for an interview at NVIDIA as a machine learning engineer, expect a mix of coding challenges, system design problems, and deep learning case studies that test your practical skills, creativity, and ability to align with NVIDIA’s mission in AI and deep learning innovation.
Coding / Technical Questions
Tests your ability to build ML models, solve algorithmic problems, and write scalable code. These are core interview questions for an AI engineer applying to high-impact roles at NVIDIA.
1. Build a model to bid on a new unseen keyword using a dataset of keywords and their bid prices.
This question assesses your ability to approach complex real-world scenarios with a structured and thoughtful methodology. To answer it well, break down the problem into manageable components, clearly state any assumptions, and walk through trade-offs or potential pitfalls. Use code snippets, math, or diagrams where relevant to communicate clarity and technical rigor. This is an opportunity to showcase both your problem-solving depth and communication skills in high-stakes, applied ML or systems contexts.
2. Determine if 1 million Seattle ride trips suffice to build an accurate ETA prediction model.
This question evaluates your statistical reasoning and modeling judgment under real-world data constraints. You should assess sample sufficiency using metrics like variance reduction, generalization, or confidence intervals. Reference how you’d test model robustness and validate performance on test or holdout data. It’s a chance to show your ability to design scalable solutions grounded in empirical thinking.
This scenario tests your ability to design end-to-end machine learning systems with a real-time component. Demonstrate how you would build a fraud detection pipeline, evaluate false positives, and implement a messaging loop for feedback. Touch on privacy, scalability, and cost constraints. It reflects how ML engineers at NVIDIA balance modeling, systems integration, and customer impact.
4. Explain why measuring bias is important in predicting food preparation times at a restaurant.
This question explores your understanding of fairness, bias, and ML ethics in operational settings. Structure your answer by identifying potential sources of bias, quantifying impact, and proposing mitigation strategies. Cite business implications (e.g., wait times, labor) and customer experience. NVIDIA values ML engineers who are thoughtful about equity in algorithmic decisions.
5. Decide how to handle missing square footage data in a Seattle housing price prediction model.
You’re being tested on your data preprocessing and imputation strategy skills here. Discuss how you’d analyze missingness patterns, test multiple imputation techniques, and measure model sensitivity to these decisions. Reference tools like MICE, KNN, or mean substitution and their trade-offs. This question is a proxy for how you clean and prep data in production ML pipelines.
Data Annotation & Deep-Learning Specific Questions
Covers data annotation NVIDIA questions and core NVIDIA deep learning interview questions. Expect challenges around labeling workflows, CNN/RNN optimization, and model training aligned with NVIDIA and deep learning priorities.
6. Explain strategies to combat overfitting in tree-based classification models.
You’re being evaluated on model generalization and regularization strategies. Reference hyperparameter tuning (max depth, min samples split), cross-validation, or ensemble learning. Support your approach with diagnostic plots or feature analysis. Controlling model complexity is crucial when NVIDIA engineers build production-grade classifiers.
7. Summarize the key differences between classification and regression models.
This checks your foundational ML literacy and communication clarity. Compare loss functions, output structure, and evaluation metrics. Use practical examples (e.g., image tagging vs. price prediction) to ground your explanation. NVIDIA values ML engineers who can contextualize their models across different problem types.
This probes your data robustness and deep learning tuning skills. Discuss label cleaning, data augmentation, attention mechanisms, or fine-tuning on curated data. You should also touch on domain transfer or architecture tweaks. In real NVIDIA projects, messy data and edge-case accuracy can make or break model utility.
You’re being asked how to evaluate unsupervised learning results without ground truth. Discuss internal metrics (e.g., silhouette score, Davies-Bouldin index) or domain-specific heuristics. Suggest visual validation or downstream performance proxies. NVIDIA engineers are expected to justify model quality even in ambiguous settings.
This question dives into optimization literacy in deep learning. Compare Adam with SGD, RMSprop, or Adagrad in terms of convergence, learning rate decay, and momentum. Illustrate impact using real training curves or model outcomes. NVIDIA deep learning interview questions often surface your grasp of tuning and training dynamics.
System / Pipeline Design Questions
Focuses on designing ML systems optimized for speed, scale, and GPU deployment—key skills for ML engineers at NVIDIA.
11. Design a classifier to predict the optimal moment for a commercial break during a video
This question evaluates your real-time inference design and understanding of temporal features. You’ll need to segment video content and define engagement signals. Use lightweight models or streaming architectures for production scalability.
12. Describe the process of building a restaurant recommender system
Recommend using collaborative filtering or content-based models depending on cold-start constraints. This is an end-to-end system design that spans data ingestion, feature pipelines, and ranking.
13. Design a recommendation algorithm for Netflix’s type-ahead search
Expect to discuss query prediction, personalization, and latency trade-offs. Address caching strategies and model update cadence. Useful for search-heavy products NVIDIA may integrate with.
14. Create a recommendation engine for rental listings
Highlight candidate generation + ranking pipelines. This is a good test of how well you understand multi-stage architecture. Tie in user preference modeling and response feedback loops.
15. Design a podcast search engine with transcript indexing
Here, you’ll touch on NLP for transcription, semantic search using embeddings, and TF-IDF or ANN-based retrieval. It’s a classic retrieval task now accelerated by vector databases.
Behavioral or Culture-Fit Questions
Evaluates your self-awareness, collaboration, and alignment with NVIDIA’s mission. Strong answers show how you grow from feedback and work across teams.
16. What would your current manager say about you? What constructive criticisms might they give?
This question tests self-awareness and openness to feedback. Share examples from past reviews and balance your strengths with areas of improvement. NVIDIA values engineers who grow through feedback loops.
17. Tell me about a time when you exceeded expectations during a project.
Use a STAR format—focus on initiative, measurable impact, and problem-solving. Projects that required deep learning innovation or MLOps work will resonate.
18. What are you looking for in your next job?
This helps assess alignment with NVIDIA’s mission and your personal growth goals. Mention learning opportunities, innovation, and contributing to ML at scale.
19. Describe a situation where you had to collaborate with a cross-functional team.
Highlight communication across hardware, software, or research roles. NVIDIA thrives on collaboration between CUDA engineers, data scientists, and system architects.
20. Can you describe a time when you dealt with conflicting priorities or stakeholder feedback?
Focus on conflict resolution, prioritization frameworks, and transparency. It’s common in fast-moving ML teams building customer-facing products.
How to Prepare for a Machine Learning Engineer Role at NVIDIA
Preparing for a machine learning engineer role at NVIDIA involves much more than just technical study. It requires a balanced focus on algorithmic depth, hands-on fluency, and thoughtful communication. Start by reviewing key mathematical foundations like linear algebra, calculus, and statistics. You should also gain mastery over classic and modern machine learning algorithms, such as decision trees, support vector machines, and neural networks. Deep learning knowledge is especially important. Make sure you understand architectures like CNNs and RNNs, and revisit any relevant content from NVIDIA’s online deep learning courses or assessments. Python is the primary language used, so be proficient with libraries such as NumPy, Pandas, scikit-learn, TensorFlow, and PyTorch. Practice data preprocessing techniques, including handling missing data and feature engineering, to strengthen your pipeline design skills.
Equally important are your soft skills. Practice explaining your thought process and results clearly, especially when your audience might not have a technical background. Structured problem-solving and the ability to apply ML solutions to real-world constraints are also key traits NVIDIA looks for. Understanding how machine learning impacts industries like autonomous driving or healthcare can help you frame your solutions in context. Finally, build a strong portfolio of projects and contribute to the ML community. This shows initiative and signals that you are already aligned with NVIDIA’s mission to drive innovation in AI and deep learning.
FAQs
What Is the Average Salary for a Machine Learning Engineer at NVIDIA?
Average Base Salary
Average Total Compensation
Where Can I Learn More About NVIDIA Interviews?
If you want a full breakdown of how NVIDIA approaches interviews across different roles—not just data science—you can check out our NVIDIA Interview Guide. It covers company-wide insights into the interview structure, cultural expectations, and what makes NVIDIA’s hiring process unique.
Are There Machine Learning Engineer Job Postings for NVIDIA on Interview Query?
Yes! The Jobs Boards hosts recent job postings for different roles at different companies, including the Machine Learning Engineer role at Nvidia.
Conclusion
The NVIDIA machine learning engineer interview is rigorous, testing both your technical depth and your ability to collaborate across engineering, research, and product teams.
Still curious about other relevant NVIDIA interview guides? Here are the links to the software engineer and data scientist positions.
Want to sharpen your skills even further before applying as a NVIDIA ML engineer? Check out our blog for practice prompts, deep dives, and insider strategies to help you get hired.
Nvidia Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
Data Structures & Algorithms | Easy | |
Data Structures & Algorithms | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences