
NVIDIA Data Engineer Interview Guide: Questions, Process, and Tips


Introduction
Preparing for the NVIDIA data engineer interview means understanding the unique intersection of massive-scale data infrastructure and cutting-edge AI applications. As a NVIDIA data engineer, you’ll own and optimize real-time data pipelines that fuel mission-critical analytics across AI model training, GPU performance monitoring, autonomous systems, and cloud services. Day-to-day, the role involves collaborating with ML researchers, product analysts, and system architects to streamline data flow from raw ingestion to actionable insight. You’ll work closely with internal platforms like RAPIDS and NVIDIA AI to ensure data integrity, latency optimization, and horizontal scalability. Engineers are expected to write production-grade code, deploy with containerized infrastructure, and contribute to tools that make AI workflows faster and more reliable.
What sets the data engineer NVIDIA role apart is the proximity to world-class innovation: you’ll be handling data that directly impacts breakthroughs in generative AI, robotics, and deep learning. Beyond the technical challenge, candidates are drawn to NVIDIA’s culture of ownership, rapid iteration, and deep respect for individual contributors. Many use this role as a launchpad into ML infrastructure or systems architecture, thanks to built-in career mobility and mentorship from top engineers in the field. Competitive RSUs and NVIDIA’s reputation for internal promotion make it one of the most attractive offers in tech. With all that in mind, let’s break down how to prepare for the NVIDIA data engineer interview.
What Is the Interview Process Like for a Data Engineer Role at NVIDIA?
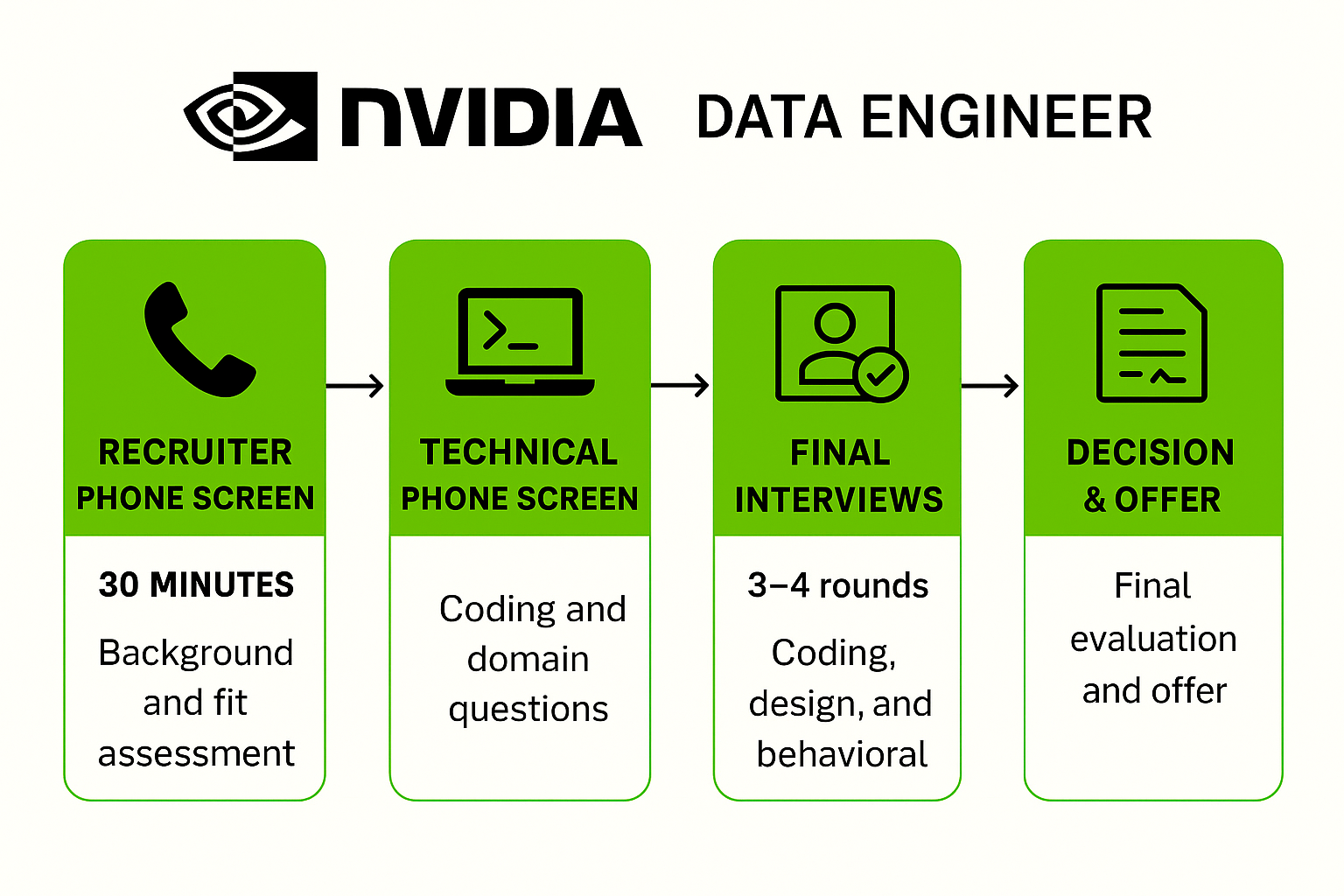
The NVIDIA data engineer interview typically spans multiple rounds designed to evaluate both technical depth and cross-functional communication. From recruiter screens to onsite design challenges, the process tests your ability to build, scale, and explain complex data systems.
Recruiter Phone Screen
Your journey typically begins with a 30-minute call with an NVIDIA recruiter. This stage covers your professional background, interest in the role, and basic fit questions—and may include 1–2 introductory technical queries like your experience with data pipelines or cloud tools. The goal is to assess your alignment with the role and gauge communication clarity early on.
Technical Phone Screen
Expect 1–2 coding challenges (data structures and algorithms) and possibly domain-specific questions relevant to data engineering (e.g., ETL tools, real-time ingestion). Interviewers evaluate problem-solving approach, clarity, and coding fluency.
Final Interviews
The final stage usually involves 3–4 rounds over several hours. These commonly include:
- Coding interviews (1–2 rounds) with one focused on general DSA and another on domain-specific problems—possibly in languages like Python, or SQL.
- System / pipeline design interview where you must architect scalable ETL workflows, modeling, storage and latency optimizations as a NVIDIA data engineer.
- Behavioral interview with stakeholders or hiring manager in STAR format.
Decision & Offer
After the final rounds, interviewers submit scorecards. Feedback is aggregated, and decisions usually come within a few weeks. If selected, you’ll receive an offer package and can negotiate it before onboarding begins.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Nvidia?
What Questions Are Asked in a NVIDIA Data Engineer Interview?
Here are a few questions that are commonly asked in NVIDIA data engineer interviews:
Coding / Technical Questions
These questions assess your technical fundamentals—how well you write code, structure logic, and apply tools like Python, SQL, and Hadoop. They’re designed to test your problem-solving ability under real-world constraints like time, memory, and clarity.
1. Format an array of words into lines of exactly max_width characters, distributing spaces evenly.
This problem is about string manipulation, greedy algorithms, and control over output formatting, commonly encountered in data reporting or front-end systems. Interviewers ask this to test your precision with iterative control flow and boundary logic. Begin by explaining how you’d construct each line word-by-word and track available space, then show how to distribute padding. Discuss time complexity and corner cases like single-word lines.
2. Find the integer removed from list X to form list Y using O(1) space and O(n) time.
This is a classic test of your ability to work with minimal memory under linear constraints. The goal is to assess whether you can use simple arithmetic tricks, like summation or XOR, to identify missing data efficiently. Start by describing the relationship between the lists, then walk through two possible solutions—sum diff and bitwise XOR—highlighting when to use which. Mention pitfalls like duplicate elements or unordered lists.
3. How would you design a data pipeline?
This question evaluates your ability to architect end-to-end data systems. Start by asking clarifying questions about the data source, expected frequency, and downstream use cases. Then, describe your choices for data ingestion, transformation, and storage, citing tools like Kafka, Spark, or Airflow. Interviewers ask this to understand how you think through performance, reliability, and scalability.
4. What are the key features of Hadoop?
This tests your understanding of distributed systems in data engineering. Describe how Hadoop provides fault tolerance via HDFS replication, parallelism through MapReduce, and scalability across commodity hardware. Highlight how you’ve used it (or alternatives like Spark) to process large datasets efficiently. This question often screens for foundational system design literacy.
5. Find the missing number from an array spanning 0 to n with one number missing.
This question is often used to test your basic algorithm skills and comfort with mathematical patterns. The interviewer wants to see if you understand efficient ways to find a missing element without sorting. Outline the arithmetic series method and, optionally, the XOR method, then walk through the logic with sample input. Focus on edge handling—like empty or full arrays—and complexity.
System / Pipeline Design Questions
System design questions focus on your ability to architect scalable, reliable, and efficient data infrastructure. Expect to discuss schema modeling, warehouse design, and trade-offs between performance and maintainability.
This tests your ability to build relational schemas and write performance-sensitive queries. It’s asked to simulate real-world transportation or IoT data scenarios. Begin by defining the primary entities and timestamps, then describe how you’d join and aggregate the data for analysis. Clarify your indexing and window function strategy for efficient results.
7. Add a column with data to a billion-row table without disrupting user experience.
This question checks your understanding of production-level data engineering concerns like schema evolution and migration strategies. Interviewers want to see how you’d avoid downtime and ensure backward compatibility. Talk through options like backfilling in batches, lazy evaluation, or deploying shadow tables. Mention monitoring and rollback plans to show operational thinking.
This is meant to test your ability to model structured transactions and derive insights. Interviewers are looking for practical knowledge of normalization and query construction. Describe the core tables (orders, menu_items, categories), then walk through your approach to grouping and filtering. Tie it back to real business reporting needs.
9. What are the features of a physical data model?
Interviewers ask this to evaluate how well you bridge logical design with real-world implementation. Highlight things like table definitions, data types, indexing, partitioning, and constraints. Discuss how physical modeling impacts performance, storage, and maintainability. This helps them assess your readiness for deployment-heavy tasks.
10. What are some things to avoid when building a data model?
This question checks your awareness of common pitfalls. Talk about inconsistent naming conventions, failing to normalize where necessary, and skipping stakeholder input. Share how poor key choices or lack of documentation can create downstream issues. It shows your experience not just in building models, but in sustaining them.
Behavioral or “Culture Fit” Questions
Behavioral questions gauge how you work with others, take ownership, and align with NVIDIA’s fast-paced, collaborative culture. They give interviewers a window into your communication style, problem-solving mindset, and growth potential.
11. Describe a situation where you had to debug a failing data pipeline in production.
This tests your troubleshooting process and ability to stay calm in high-stakes situations. The interviewer wants to see how you isolate issues, communicate with teams, and prevent future recurrences. Share a concrete example and break down the steps you took. Emphasize root cause analysis and follow-up improvements.
12. Tell me about a time you disagreed with a team decision. What did you do?
This is about your ability to navigate conflict and advocate for your viewpoint constructively. Interviewers want to hear that you can balance assertiveness with team harmony. Share a story where you voiced disagreement respectfully, presented data, and collaborated on a resolution. It shows emotional intelligence and team fit.
13. How would you convey insights and the methods you use to a non-technical audience?
This evaluates communication and stakeholder empathy. Describe how you simplify terminology, use analogies, or tell data-driven stories through visuals like dashboards or slide decks. Include an example where your explanation led to buy-in or action. It shows your ability to bridge technical depth with business context.
14. Describe a data engineering problem you have faced. What were some challenges?
This explores your problem-solving approach and resilience. Talk through a technical challenge—like a broken pipeline or mismatched schemas—focusing on how you diagnosed and resolved it. Highlight any collaboration, trade-offs made, and what you learned. It gives the interviewer insight into how you handle ambiguity and pressure.
15. Tell me about when you used data to influence a decision or solve a problem.
This assesses your ability to translate data into business action. Describe the context, how you collected and analyzed the data, and what insights you generated. Walk through how you communicated those findings and what decisions followed. The focus is on end-to-end ownership, not just analysis.
How to Prepare for a Data Engineer Role at NVIDIA
Preparing for a data engineer role at NVIDIA means building expertise in scalable systems, sharpening your coding and deployment skills, and aligning closely with the company’s AI-driven mission.
Preparation Tips
To succeed in the NVIDIA data engineer interview, you’ll need to blend systems thinking with strong coding fundamentals and demonstrate how you support AI-driven innovation through resilient data pipelines. Here’s how to prepare thoroughly:
Understand the Role of a NVIDIA Data Engineer
Dive into how NVIDIA builds real-time data systems for AI, robotics, and GPU infrastructure. Study tools like RAPIDS, Kafka, and Airflow, and understand how they’re used in production to support generative AI and autonomous systems. A strong NVIDIA data engineer demonstrates ownership of data flows from ingestion to insight and contributes directly to ML platform reliability.
Sharpen Your SQL, Python, and System Design Skills
Practice window functions, optimization strategies, and writing clean, testable Python code. Also review how to design horizontally scalable ETL systems and data lakes under real-time constraints.
Brush Up on Infrastructure and Deployment Concepts
NVIDIA expects data engineers to write production-grade code and understand containerization, CI/CD pipelines, and fault tolerance. You may be asked how to backfill a billion-row table or evolve schemas without downtime. Focus on high-availability systems and monitoring best practices.
Mock System Design and Debugging Interviews
The system/pipeline round evaluates how you approach ambiguity and scale. Practice designing from scratch with open-ended prompts, explaining trade-offs between cost, latency, and complexity. If possible, get feedback from peers or mentors, especially on how you handle bottlenecks or design recovery mechanisms.
Think Cross-Functionally
As a NVIDIA Data Engineer, you’ll collaborate with ML researchers, analysts, and platform teams. Prepare examples of how you’ve worked across teams, translated needs into specs, and debugged production issues quickly. This cross-functional fluency is key to standing out.
Practice STAR-Based Behavioral Answers
NVIDIA values initiative and low-ego execution. Use the STAR framework to share stories where you owned a complex pipeline, led postmortems, or reduced latency through clever optimizations. Interviewers look for autonomy, curiosity, and scalable thinking.
With a structured plan and clear communication, you’ll be well-equipped to ace the NVIDIA data engineer interview and join a team shaping the future of AI infrastructure.
FAQs
What Is the Average Salary for a Data Engineer at NVIDIA?
Average Base Salary
Average Total Compensation
Where Can I Learn More About NVIDIA Interview?
If you want a full breakdown of how NVIDIA approaches interviews across different roles—not just data science—you can check out our NVIDIA Interview Guide. It covers company-wide insights into the interview structure, cultural expectations, and what makes NVIDIA’s hiring process unique.
Are There Job Postings for NVIDIA Data Engineer Roles on Interview Query?
Yes! The Jobs Boards hosts recent job postings for different roles at different companies, including the Data Engineer role at Nvidia.
Conclusion
The NVIDIA data engineer interview is both technical and strategic—designed to identify candidates who can build scalable infrastructure while working seamlessly across data, ML, and product teams. Success comes down to mastering real-time data systems, communicating clearly under pressure, and demonstrating initiative in ambiguous problem spaces. With thoughtful preparation and hands-on practice, you’ll be in a strong position to stand out from other applicants.
Looking to apply as a NVIDIA data engineer? Explore more insights and role-specific prep by visiting our machine learning engineer and data scientist interview guides.
Need more practice or insider tips? Check out our blog for practice prompts, deep dives, and insider strategies to help you get hired.
NVIDIA Data Engineer Jobs
Nvidia Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
SQL | Hard | |
Data Structures & Algorithms | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences