
Meesho Data Engineer Interview Guide: Process, Questions & Prep


Introduction
A Meesho data engineer interview is built around a single reality: Meesho operates one of the largest data footprints in Indian consumer internet. The platform supports 100+ million annual transacting users, 5+ million sellers, and generates billions of events per day across discovery, pricing, logistics, payments, and post-order flows. Every business decision, from seller incentives to delivery SLAs, depends on data systems that are fast, reliable, and cost-efficient at scale.
That scale defines the interview. Meesho data engineers are evaluated on more than syntax or tool familiarity. Interviewers look for candidates who can design end-to-end data pipelines, reason about distributed processing, and maintain data quality across petabyte-scale batch and streaming workloads. In this guide, we break down the Meesho data engineer interview process, explain what each stage is designed to assess, and show how to prepare for the technical depth and ownership Meesho’s data teams expect.
Meesho Data Engineer Interview Process
The Meesho data engineer interview process is designed to evaluate how candidates operate in large-scale, distributed data environments. Rather than testing tools in isolation, Meesho focuses on whether you can design robust pipelines, model data correctly, and reason about performance, cost, and reliability under real business constraints. Most candidates complete the process in three to five weeks, depending on role level and team alignment.
Interview Process Overview
Candidates typically progress through resume screening, an online assessment, two to three technical interviews, and a final hiring manager or culture-fit round. Compared with software engineering interviews, Meesho’s data engineer process places heavier emphasis on SQL depth, data modeling, ETL design, and distributed computing concepts alongside core DSA.
Interview Process Summary
| Interview stage | What happens |
|---|---|
| Resume screening | Evaluation of data engineering experience, scale, and ownership |
| Online assessment | MCQs, DSA problems, and SQL queries on HackerEarth or Rank |
| Technical interviews | Coding/DSA, SQL & data modeling, and core data engineering concepts |
| System design (data-focused) | End-to-end pipeline, warehouse, or streaming system design |
| Hiring manager / behavioral | Ownership, problem-solving approach, and culture alignment |
Resume Screening
Resume screening focuses on scale, data ownership, and impact, not just tools. Strong resumes clearly show what data problem you solved, the volume or complexity involved, and how your work improved reliability, performance, or business outcomes. Listing technologies without context or results rarely passes this stage.
Candidates with experience in Spark-based processing, streaming systems, data lakes, or high-volume SQL workloads tend to stand out, especially when they can articulate trade-offs they made.
Meesho-specific tip: Quantify scale wherever possible, such as data volume, pipeline frequency, latency improvements, or cost reductions.
Online Assessment
The online assessment is usually a HackerEarth or Rank test combining multiple-choice questions, DSA problems, and SQL exercises. DSA questions often involve graphs, trees, or dynamic programming, while SQL questions test joins, aggregations, and window functions.
The goal is to assess foundational problem-solving ability and SQL fluency under time constraints. Correctness and clarity matter more than obscure optimizations.
Candidates often prepare for this stage by reinforcing fundamentals through the data engineering interview learning path.
Meesho-specific tip: Practice writing SQL that is both correct and readable. Interviewers care about logic as much as results.
Technical Interviews
Technical interviews for Meesho data engineer roles are designed to evaluate how well you operate in large-scale, distributed data environments. Interviewers assess not just tool familiarity, but how you reason about data flow, correctness, scalability, and operational risk. Most candidates go through two to three technical rounds, each with a distinct focus.
| Interview focus | What is evaluated |
|---|---|
| Coding & DSA | Problem-solving using graphs, trees, DFS, DP, and arrays, with emphasis on optimization and clear reasoning |
| SQL & data modeling | Complex SQL queries (joins, window functions, CTEs), schema design, and modeling fact–dimension tables for e-commerce use cases |
| Core data engineering | ETL/ELT design, Spark execution concepts, batch vs streaming trade-offs, and handling schema evolution |
| Data system design | End-to-end pipeline or data platform design covering ingestion, storage, processing, partitioning, and reliability |
| Debugging & optimization | Identifying performance bottlenecks, data quality issues, and cost inefficiencies in existing pipelines |
Candidates may be asked to design or critique systems involving data lakes, warehouses, or streaming pipelines using tools such as Spark, Kafka, or Delta Lake. Interviewers often probe how your design behaves under scale, schema changes, or upstream failures.
Meesho-specific tip: Always explain how you validate data, monitor pipelines, and recover from failures, not just how data flows when everything works.
Hiring Manager Or Behavioral Round
The final round focuses on ownership, collaboration, and alignment with Meesho’s growth-oriented culture. Interviewers assess how you approach ambiguous data problems, work across teams, and balance speed with data correctness.
Questions often explore how you handled pipeline failures, schema changes, or competing stakeholder requirements.
Meesho-specific tip: Emphasize end-to-end responsibility, not just implementation details.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Meesho?
Meesho Data Engineer Interview Questions
Meesho data engineer interview questions are designed to assess whether you can reason clearly about large-scale data systems while maintaining correctness, efficiency, and reliability. Interviewers focus on how you structure problems, justify trade-offs, and design solutions that remain stable as data volume and business complexity grow. Strong candidates consistently explain why an approach works, not just what it does.
Because the role blends software engineering fundamentals with analytics infrastructure, questions typically span algorithmic reasoning, SQL depth, and data modeling for real e-commerce use cases.
Coding & Algorithmic Foundations
Although data engineers are not expected to solve competitive programming problems daily, Meesho expects solid algorithmic fundamentals. These questions evaluate your ability to reason under constraints, optimize for scale, and avoid inefficiencies that become costly in distributed systems.
How would you calculate the maximum profit from at most two buy–sell transactions?
This question evaluates your ability to model state and optimize decisions over time. Strong answers clearly define state variables, explain how transitions preserve optimality, and reason about time and space complexity. Interviewers care more about how you structure the solution than the final formula.
Tip: Walk through a concrete example and explain how each state update avoids double-counting profits.
How would you select a random element from a data stream using O(1) space?
This tests probabilistic reasoning under strict memory constraints, which mirrors real streaming data scenarios. Strong candidates explain reservoir sampling intuitively and justify why each element has equal probability despite the stream length being unknown. Interviewers may probe edge cases such as infinite streams or very high throughput.
Tip: Focus on why uniform randomness is preserved, not just how the algorithm works.
How would you model a two-day Markov rain process and compute the probability of rain on day n?
This question assesses structured reasoning and state representation. Strong answers focus on constructing the transition matrix, defining the state vector, and explaining how matrix exponentiation enables efficient computation for large n. The emphasis is on scalability and clarity rather than numerical precision.
Tip: Explain how your approach avoids O(n) iteration when n becomes very large.
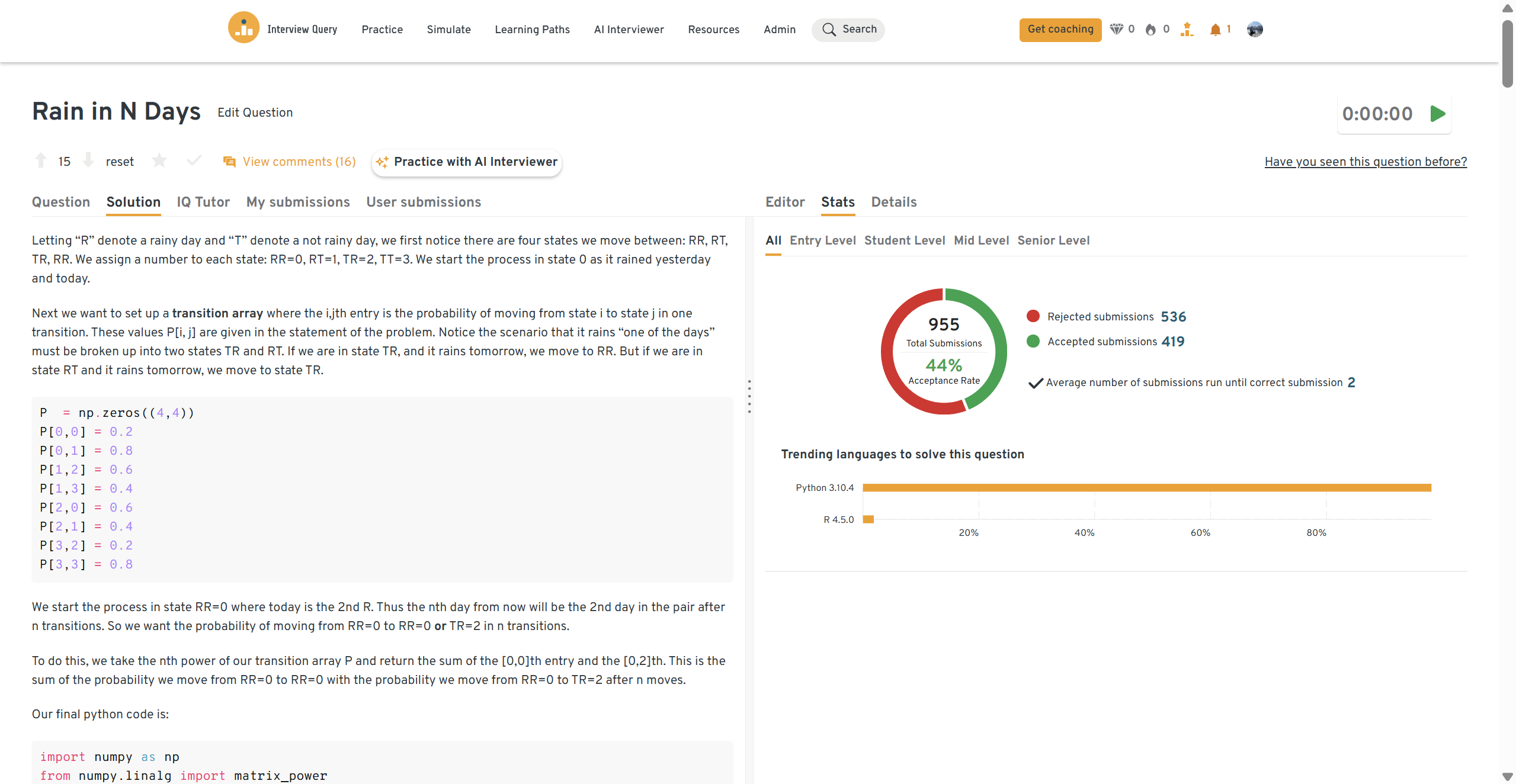
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
SQL & Data Modeling Questions
SQL depth is one of the strongest differentiators for Meesho data engineers. Interviewers expect candidates to write correct, readable queries and to reason about schema design, performance, and analytical use cases at scale.
Write a SQL query to count transactions filtered by multiple criteria.
This question evaluates filtering logic, grouping, and aggregation on large transactional tables. Strong candidates clearly explain how they structure WHERE clauses, avoid double-counting, and ensure correctness across edge cases. Interviewers often look for awareness of how such queries behave on very large datasets.
Tip: Mention how indexing or partitioning could improve performance in production.
Write a query to return records that have not yet been processed or scraped.
This tests your understanding of set differences and data completeness. Strong answers clearly articulate assumptions about nulls, missing records, and primary keys, and choose an approach such as LEFT JOIN or NOT EXISTS deliberately.
Tip: Explain why your chosen method is safer than alternatives in the presence of null values.
Design a data model for an online retailer’s analytics use cases.
This question assesses your ability to translate business questions into a scalable schema. Strong candidates propose a fact–dimension model, justify granularity decisions, and explain how the model supports common queries such as revenue trends or cohort analysis.
Tip: Anchor your schema choices to specific analytics questions rather than abstract best practices.
Design an end-to-end data pipeline to process and serve analytics data.
Interviewers use this to evaluate system-level thinking across ingestion, storage, processing, and consumption. Strong answers describe how data flows through the system, how failures are detected, and how downstream consumers are protected from bad data.
Tip: Always discuss monitoring, validation checks, and recovery strategies, not just the happy path.
Behavioral & Ownership Questions
Behavioral interviews for Meesho data engineer roles focus on ownership, judgment, and reliability under scale. Interviewers want to understand how you operate when pipelines break, data quality is compromised, or requirements change mid-flight. Strong candidates demonstrate structured thinking, accountability, and the ability to balance speed with correctness.
Tell me about a time a data pipeline failed in production. How did you handle it?
This question evaluates incident response, root cause analysis, and prevention mindset. Interviewers care about how you contain blast radius, communicate impact, and ensure the issue does not recur.
Tip: Emphasize stabilization first, then long-term fixes.
Sample answer: One of our daily aggregation pipelines failed due to an upstream schema change that removed a required column. I first paused downstream dashboards to prevent incorrect data from being consumed, then worked with the source team to confirm the change. After fixing the transformation logic, I added schema validation checks and alerts at ingestion. I also documented the dependency so future changes would be flagged earlier. As a result, similar failures were caught before reaching production in subsequent releases.
Describe a time you had to balance data quality with delivery speed.
This assesses judgment under pressure and your ability to make pragmatic trade-offs. Interviewers want to see that you protect trust in data while still enabling business progress.
Tip: Show how you made limitations explicit rather than hiding them.
Sample answer: We were asked to deliver a metrics dashboard for a leadership review, but part of the historical data was incomplete due to delayed ingestion. I shipped an initial version using validated recent data and clearly annotated the gaps. In parallel, I fixed the backfill pipeline and scheduled an update once data quality was restored. This allowed stakeholders to make timely decisions without misleading them. It also reinforced confidence in the data team’s transparency.
Tell me about a data modeling decision you later had to revisit.
This question evaluates learning, adaptability, and long-term thinking. Interviewers look for evidence that you can course-correct without creating instability.
Tip: Focus on why the original decision made sense at the time.
Sample answer: I initially modeled a reporting table as a wide denormalized schema to simplify analyst queries. As usage grew, the table became expensive to maintain and slow to update when dimensions changed. After observing query patterns, I redesigned the model into a fact–dimension structure and migrated consumers incrementally. I communicated changes early and provided backward-compatible views during the transition. The new model improved performance and reduced maintenance overhead.
How do you handle ambiguous requirements from analytics or business teams?
This evaluates communication skills and problem framing. Interviewers want to see how you turn vague asks into concrete, testable data work.
Tip: Show how you reduce ambiguity before building.
Sample answer: When requirements are unclear, I start by clarifying what decisions the data is meant to support. I propose sample queries or mock outputs to validate assumptions early. This often surfaces hidden constraints or missing definitions. Once aligned, I build incrementally so changes are easier to absorb. This approach has consistently reduced rework and misalignment.
Tell me about a time you improved a data system beyond your assigned scope.
This assesses ownership and initiative. Meesho values data engineers who think in terms of system outcomes, not just tickets.
Tip: Highlight measurable impact.
Sample answer: While working on a feature pipeline, I noticed repeated delays caused by inefficient partitioning in our Spark jobs. Although it wasn’t part of my task, I refactored the partition strategy and added adaptive query execution. This reduced job runtime by about 35 percent and lowered compute costs. I shared the changes with the team and documented best practices. It improved reliability across multiple pipelines.
If you want deeper practice, you can explore the full set of 100+ data engineer interview questions with answers. This walkthrough by Interview Query founder Jay Feng covers 10+ essential data engineering interview questions—spanning SQL, distributed systems, pipeline design, and data modeling.
How To Prepare For A Meesho Data Engineer Interview
Meesho data engineer interviews reward candidates who can combine strong fundamentals with practical judgment in large-scale data systems. Preparation should reflect the reality of the role: operating distributed pipelines, maintaining data quality, and supporting fast-moving business teams without compromising reliability. Focusing only on tools or theory is not sufficient.
Build strong depth in SQL and data modeling.
SQL is one of the most heavily weighted skills in Meesho’s data engineer interviews. You should be fluent in joins, window functions, CTEs, aggregations, and subqueries, and able to explain query behavior on large datasets. Practice writing readable SQL and articulating why a particular structure is correct and performant. Structured repetition through the data engineering interview learning path helps reinforce these patterns.
Strengthen algorithmic fundamentals with scale in mind.
While you will not be asked competitive programming puzzles daily, Meesho expects solid reasoning around graphs, trees, recursion, and dynamic programming. Interviewers care about how you model problems and avoid inefficient solutions that break at scale. Focus on correctness, time–space trade-offs, and explaining your approach clearly.
Prepare for data system design and ETL discussions.
System design rounds often focus on end-to-end data pipelines, warehouses, or streaming architectures. You should be able to design ingestion, transformation, and serving layers, and explain decisions around partitioning, schema evolution, and failure handling. Practicing applied prompts from the challenges library helps build comfort with these discussions.
Get comfortable reasoning about Spark and distributed processing.
Interviewers frequently probe how Spark jobs execute, where bottlenecks arise, and how you would optimize performance or cost. Be prepared to discuss shuffles, partitions, joins, and caching at a conceptual level, even if you are not writing code in the interview.
Prepare behavioral stories that show ownership of data systems.
Meesho places strong emphasis on ownership and reliability. You should prepare examples where you handled pipeline failures, managed schema changes, or balanced delivery speed with data quality. Practicing aloud through mock interviews helps refine clarity and confidence without sounding scripted.
Role Overview And Culture At Meesho
A Meesho data engineer builds the data foundation that enables analytics, experimentation, and decision-making across one of India’s largest e-commerce platforms. The role centers on designing and operating scalable pipelines that handle high-volume batch and streaming data while maintaining correctness, reliability, and cost efficiency.
Day to day, the work typically includes:
- Pipeline development: building and maintaining batch and streaming pipelines that ingest, transform, and serve data reliably.
- Data modeling and architecture: designing schemas for data lakes and warehouses that support analytics, reporting, and experimentation.
- Performance and cost optimization: tuning Spark jobs, partitioning strategies, and storage layouts to balance speed and infrastructure cost.
- Data quality and reliability: implementing validation checks, monitoring, and alerting to ensure trust in downstream data.
- Cross-functional collaboration: working closely with data scientists, analysts, backend engineers, and product teams to align data systems with business needs.
Culturally, Meesho emphasizes ownership, impact, and pragmatism. Data engineers are expected to take end-to-end responsibility for the systems they build, anticipate failure modes, and raise risks early. Teams move quickly, but not at the expense of data correctness or long-term maintainability.
The environment is collaborative and growth-oriented. Engineers are encouraged to improve existing systems, introduce better tooling, and share best practices across teams. Success is measured not only by shipping pipelines, but by how reliably data supports business decisions at scale.
From a career perspective, the role offers deep exposure to distributed data systems, real-time analytics, and high-impact business problems. Data engineers can grow into platform specialists, technical leads, or broader data architecture roles as the organization scales.
FAQs
How long does the Meesho data engineer interview process take?
Most Meesho data engineer candidates complete the interview process in three to five weeks, depending on team availability and role seniority. Online assessments and early technical rounds typically move quickly, while later system design or hiring manager rounds may take longer due to scheduling.
How technical is the Meesho data engineer interview?
The interview is highly technical, with strong emphasis on SQL, data modeling, ETL design, and distributed data systems. Candidates are also evaluated on algorithmic fundamentals and their ability to reason about scalability, reliability, and cost in production data pipelines.
What SQL topics should I focus on for Meesho data engineer interviews?
You should be comfortable with joins, window functions, CTEs, aggregations, and subqueries, and able to explain query behavior on large datasets. Interviewers often probe correctness, edge cases, and performance considerations rather than just syntax.
Does Meesho ask system design questions for data engineers?
Yes. System design is a core component of Meesho data engineer interviews, especially for mid-level and senior roles. Candidates are expected to design end-to-end data pipelines, data lakes or warehouses, and streaming systems, and to explain trade-offs around partitioning, schema evolution, and failure handling.
What does Meesho look for in strong data engineer candidates?
Strong candidates demonstrate ownership of data systems, clear reasoning under scale, and disciplined engineering judgment. Meesho values engineers who can balance delivery speed with data correctness and who proactively identify risks in pipelines and architectures before they impact the business.
Is prior Spark or big data experience required?
Hands-on experience with Spark or similar distributed processing frameworks is strongly preferred, especially for senior roles. Interviewers expect conceptual understanding of how distributed jobs execute, where bottlenecks arise, and how to optimize performance and cost.
Prepare Like A Data Platform Owner
Meesho data engineer interviews are designed to identify engineers who can be trusted with the backbone of the company’s data platform. Interviewers evaluate how you reason about distributed systems, how you protect data quality at scale, and how you take responsibility when pipelines power critical business decisions.
The most effective preparation mirrors that reality. Build deep SQL and data modeling fluency through structured practice in the data engineering interview learning path. Strengthen your system design instincts with applied scenarios from challenges and longer-form takehomes. Finally, pressure-test your explanations and ownership stories through realistic mock interviews or personalized coaching.
With disciplined preparation and a platform-owner mindset, you can walk into the Meesho data engineer interview ready to design systems that scale, stay reliable, and earn trust across the organization.
Meesho Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||||||||
Let’s say you work at a file-hosting website. You have information on user’s daily downloads in the Use the window function Example: Input:
Output:
| ||||||||||||||||||||
SQL | Medium | |||||||||||||||||||
Data Structures & Algorithms | Hard | |||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences