
Meesho Data Scientist Interview Guide: Process, Questions & Prep


Introduction
A Meesho data scientist interview is designed to answer one central question: can you use data and machine learning to drive real business outcomes at massive scale? Meesho supports 100+ million users and millions of resellers and sellers, operating in a social-commerce ecosystem where price sensitivity, trust, and discovery behavior differ sharply from traditional e-commerce.
That scale fundamentally shapes the interview. Meesho data scientists are evaluated not just on model accuracy or theory, but on their ability to design experiments, reason through trade-offs, and translate insights into production-ready solutions. Whether the problem involves recommendations, fraud detection, search relevance, or ads monetization, interviewers expect candidates to connect technical decisions to measurable impact. In this guide, we break down the Meesho data scientist interview process, explain what each stage is designed to assess, and show how to prepare for the blend of machine learning depth, coding rigor, and business judgment Meesho looks for.
Meesho Data Scientist Interview Process
The Meesho data scientist interview process is designed to evaluate technical depth, analytical rigor, and ownership across the full data science lifecycle. Rather than testing isolated skills, Meesho assesses how well candidates integrate coding, machine learning, statistics, and business reasoning to solve real problems. Most candidates complete the process in four to seven weeks, depending on role seniority and scheduling.
Interview Process Overview
Candidates typically progress through resume screening, an online assessment, and multiple technical interviews covering machine learning fundamentals, coding and DSA, system design, and business impact. Compared with research-only roles, Meesho places heavier emphasis on end-to-end problem solving, from data extraction and modeling to experimentation and decision-making.
Candidates preparing for these stages often reinforce fundamentals using Interview Query’s learning paths and pressure-test their reasoning through mock interviews.
Interview Process Summary
| Interview stage | What happens |
|---|---|
| Resume screening | Recruiters assess project depth, ownership, and measurable impact |
| Online assessment | MCQs (ML, stats), DSA problems (DP, graphs), and SQL |
| Technical interviews (ML, coding, system design) | ML fundamentals, coding, SQL, system design, and deeper ML concepts |
| Hiring manager / business round | Case-based reasoning, impact, ownership, and culture fit |
Resume Screening
Resume screening is more selective for data scientist roles than for general analytics positions. Recruiters look for clear evidence of ownership, not just familiarity with tools. Strong resumes show how you framed the problem, chose methods, evaluated results, and influenced outcomes.
Candidates with experience in recommendations, experimentation, fraud detection, or large-scale behavioral analysis tend to stand out.
Meesho-specific tip: Explicitly state the metric or business outcome your work impacted.
Online Assessment
The online assessment typically includes MCQs on machine learning and statistics, 2–3 DSA problems (often dynamic programming or graph-based), and SQL queries. This stage validates baseline technical competence before deeper interviews.
Because this round spans multiple domains, many candidates prepare by practicing mixed-format questions from the data science interview learning path.
Meesho-specific tip: Practice switching quickly between SQL, ML theory, and coding without losing clarity.
Technical Interviews: Machine Learning, Coding, And System Design
Meesho usually conducts two technical interviews, but they function as a single evaluation block covering complementary dimensions of data science. Interviewers assess both depth and breadth, moving fluidly between theory, implementation, and system-level thinking.
| Focus area | What is evaluated |
|---|---|
| Machine learning fundamentals | Bias–variance tradeoff, overfitting, regularization, evaluation metrics |
| Statistics & probability | Hypothesis testing, p-values, MLE vs. MAP, distributions |
| Coding & DSA | Python-based problem solving, DP, graphs, time–space complexity |
| SQL & data handling | Joins, window functions, aggregations, data extraction logic |
| ML system design | End-to-end design for use cases like recommendations or visual search |
| Deep learning concepts (select roles) | CNNs, transformers, embeddings, representation learning |
Interviews often begin with a project deep dive, where candidates explain past work in detail before moving into live problem solving or system design. Strong candidates connect theoretical choices to practical constraints such as data quality, latency, and scalability.
Candidates often practice these integrated discussions using applied prompts from the challenges library.
Meesho-specific tip: When proposing a model or system, always explain how you would measure success and iterate.
Hiring Manager And Business Round
The final round focuses on business judgment, ownership, and cultural alignment. Candidates are given case-style questions that test how they use data to make decisions under ambiguity and how they collaborate across product, engineering, and business teams.
Interviewers look for clarity of thinking, accountability, and learning orientation rather than perfect outcomes. Many candidates refine behavioral responses through mock interviews or guided coaching.
Meesho-specific tip: Emphasize impact, trade-offs, and what you learned from imperfect results.
Challenge
Check your skills...
How prepared are you for working as a Data Scientist at Meesho?
Meesho Data Scientist Interview Questions
Meesho data scientist interview questions are designed to evaluate whether you can apply machine learning, statistics, and analytical reasoning to real product and operational problems at scale. Interviewers care less about textbook correctness and more about how you connect modeling choices, experimentation, and metrics to business impact across Meesho’s social commerce ecosystem.
Because the role spans recommendations, fraud, logistics, monetization, and experimentation, questions often blend ML theory, system thinking, and product judgment. Many candidates prepare for these rounds using applied prompts from Interview Query’s data science challenges and reinforce fundamentals through the data science interview learning path.
Machine Learning & Statistical Foundations
These questions test whether you understand how and why models work, not just how to train them. Interviewers probe statistical intuition, robustness, and generalization.
-
This question evaluates your understanding of resampling methods and uncertainty estimation when closed-form confidence intervals are unavailable. Strong candidates explain when bootstrapping is appropriate, how many samples are needed, and how to interpret the resulting interval.
Meesho tip: Connect confidence intervals to experiment analysis or seller metrics with limited data.
-
Interviewers assess ownership, risk awareness, and evaluation discipline. Strong answers walk through performance validation, assumption checks, data drift detection, and how you prioritize improvements.
Meesho tip: Emphasize validating the model against current reseller and customer behavior, not just historical results.
-
This question tests your ability to move from experimentation to production responsibly. Interviewers look for discussion of validation strategies, monitoring, retraining plans, and safeguards against degradation.
Meesho tip: Tie generalization risks to onboarding new resellers or expanding into new regions.
-
This evaluates awareness of real-world ML failure modes such as latency, feedback loops, cold start, and data quality issues. Strong candidates focus on mitigation strategies, not just idealized model performance.
Meesho tip: Frame challenges in terms of user trust and marketplace stability.
These questions assess how you apply data science to messy, real-world problems involving bias, ambiguity, and stakeholder trade-offs.
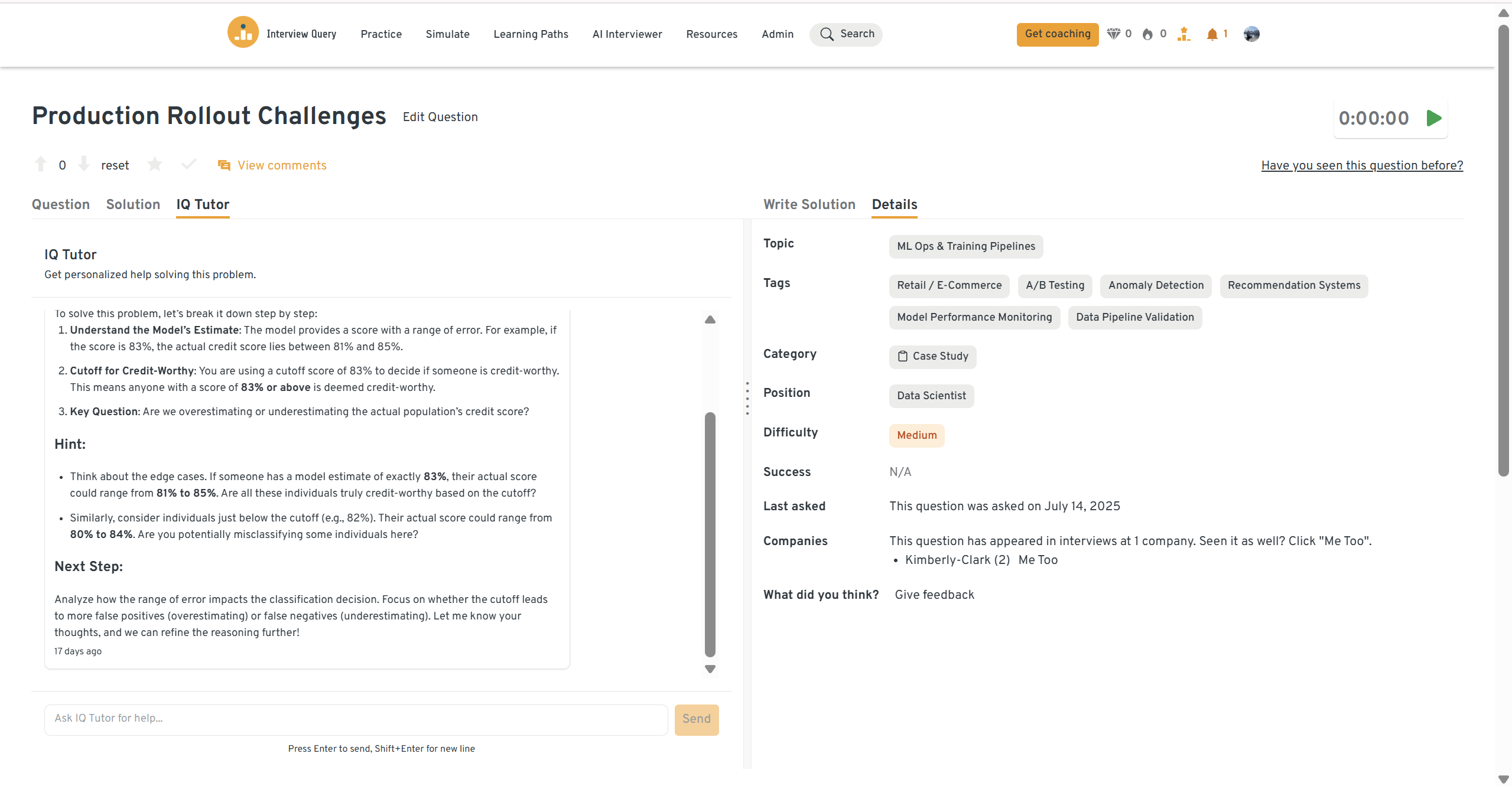
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
Experimentation, Metrics & Product Impact
These questions evaluate how you design experiments, reason about metrics, and diagnose product outcomes using data.
How would you diagnose a drop in user engagement after launching a new feature?
Interviewers want to see structured diagnosis rather than reactive fixes. Strong answers include segmentation, metric validation, hypothesis generation, and controlled follow-up experiments.
Meesho tip: Consider friction and trust effects common in social commerce flows.
-
This question evaluates metric prioritization and executive communication. Interviewers look for clarity, signal-to-noise discipline, and alignment with business goals.
Meesho tip: Translate the dashboard to seller performance, logistics SLAs, or reseller engagement.
How would you measure whether users meaningfully engage with content shortly after it is created?
This tests event-based metric design and SQL reasoning. Strong candidates carefully define engagement, time windows, and joins to avoid misleading conclusions.
Meesho tip: Tie engagement metrics to downstream outcomes like conversion or repeat usage.
How would you frame late deliveries as a data science problem and design a solution end to end?
Interviewers assess problem framing, algorithm selection, and deployment thinking. Strong answers connect modeling decisions to operational and customer impact.
Meesho tip: Link delivery performance to reseller trust and customer retention.
Applied Data Science & Business Reasoning
These questions assess how you apply data science to messy, real-world problems involving bias, ambiguity, and stakeholder trade-offs.
-
This tests fairness awareness and evaluation strategy. Interviewers want structured methods for bias detection, monitoring, and mitigation rather than vague ethical statements.
Meesho tip: Relate bias risks to seller ranking, recommendations, or moderation systems.
-
This evaluates low-level data handling and reproducibility. Strong candidates discuss randomness control, leakage prevention, and scalability.
Meesho tip: Frame this in the context of offline experiments or ML pipelines.
How would you design a recommendation system for resellers with limited historical data?
Interviewers assess cold-start strategy and practical ML judgment. Strong answers emphasize hybrid approaches, proxy signals, and fast learning loops.
Meesho tip: Prioritize simplicity and iteration speed over complex architectures early on.
How would you evaluate the success of an ML-driven feature beyond offline model accuracy?
This tests business alignment and metric discipline. Interviewers look for online metrics, guardrails, and long-term health indicators.
Meesho tip: Always include counter-metrics to prevent unintended consequences.
Behavioral Interview Questions
These questions assess how you demonstrate ownership, decision-making under ambiguity, and the ability to translate data science work into real business impact within fast-moving, imperfect environments.
Tell me about a time you deployed a model or analysis that did not perform as expected. What did you do next?
This evaluates accountability and learning orientation. Interviewers want to see how you diagnose failure in production, respond to real-world signals, and iterate rather than defending offline performance.
Meesho tip: Focus on how you identified the issue using data and what you changed in your process afterward.
Sample answer: I deployed a demand-forecasting model that showed strong offline accuracy but led to higher stockouts after launch. By comparing live error distributions to validation data, I found that recent pricing changes had shifted demand patterns. I rolled back the model, shortened retraining windows, and added guardrail metrics tied to fulfillment rate. The updated approach reduced forecast error by 17% and stabilized operations within two weeks.
Describe a situation where stakeholders disagreed with your data-driven recommendation. How did you handle it?
This tests communication and influence. Meesho interviewers want to see whether you can explain trade-offs clearly, adapt to business context, and still anchor decisions in data.
Meesho tip: Emphasize framing data in terms of business risk and impact, not statistical detail.
Sample answer: I recommended removing a feature that reduced long-term retention despite increasing short-term engagement. Product stakeholders initially pushed back because the top-line metric looked positive. I reframed the analysis around cohort retention and downstream revenue impact, showing a 6% drop in repeat usage. We ran a controlled experiment, confirmed the effect, and aligned on a revised rollout strategy.
Tell me about a time you had to make a decision with incomplete or messy data.
This evaluates judgment under uncertainty. Interviewers look for candidates who can move forward responsibly without waiting for perfect data.
Meesho tip: Highlight assumptions you made explicit and how you mitigated risk.
Sample answer: While analyzing delivery delays, event-level data was partially missing due to logging gaps. I combined available timestamps with proxy signals like hub-level backlog and historical delivery distributions. I clearly documented assumptions and validated conclusions with a small pilot before scaling. This helped reduce late deliveries by 9% while we worked on improving instrumentation.
Tell me about a project where your work had a clear business impact.
This assesses whether you can connect data science work to measurable outcomes. Meesho values impact over technical novelty.
Meesho tip: Quantify the result and explain why it mattered to the business.
Sample answer: I built a ranking adjustment model that prioritized reliable sellers during peak demand periods. After launch, order cancellations dropped by 11% and seller NPS improved by 8 points. The model was later integrated as a default signal in the ranking pipeline during sales events.
Describe a time you had to balance speed versus correctness in a data science project.
This tests prioritization and pragmatism. Interviewers want to see whether you can ship responsibly under time pressure.
Meesho tip: Show how you used guardrails or phased rollouts to manage risk.
Sample answer: For a fraud-detection use case, we needed a quick intervention before a major sale. Instead of waiting for a complex model, I shipped a rule-based baseline with clear monitoring metrics. We reduced fraudulent transactions by 22% immediately, then iterated toward a more sophisticated model post-event.
You might think that behavioral interview questions are the least important, but they can quietly cost you the entire interview. In this video, Interview Query co-founder Jay Feng breaks down the most common behavioral questions and offers a clean framework for answering them effectively.
[](url)
How to Prepare for a Meesho Data Scientist Interview
Preparing for a Meesho data scientist interview requires balancing machine learning fundamentals, coding rigor, and real-world business judgment. The process rewards candidates who can move from data to decisions under imperfect conditions, rather than those who rely purely on theory or model sophistication.
Build strong machine learning fundamentals with a focus on application.
Meesho data scientists are expected to understand why models work and when they fail. Focus on bias–variance tradeoffs, evaluation metrics, regularization, and failure modes, and practice explaining these concepts in the context of real use cases such as recommendations, fraud detection, or demand forecasting. Reinforcing these concepts through the data science interview learning path helps build intuition that translates well to Meesho-style interviews.
Practice coding and SQL as problem-solving tools, not isolated skills.
Coding and SQL are used to test structured thinking rather than syntax memorization. You should be comfortable solving Python-based DSA problems, writing clean SQL with joins and window functions, and explaining your logic clearly. Practicing under time pressure with realistic prompts from challenges helps simulate the pace and ambiguity of live interviews.
Prepare to reason end to end, from data to impact.
Many questions are framed as open-ended business problems: a metric dropped, a model underperformed, or an operational issue emerged. Rehearse a consistent approach—clarify the objective, define success metrics, propose a solution, and explain how you would validate and iterate. Longer-form exercises such as takehomes are particularly useful for building this muscle.
Sharpen communication for cross-functional audiences.
Meesho data scientists work closely with product managers, engineers, and operations teams, so clarity matters as much as correctness. Practice explaining the same insight at different levels of detail, from a technical deep dive to an executive summary. Live practice through mock interviews or targeted feedback via coaching can help refine pacing and structure.
Role Overview and Culture at Meesho
A Meesho data scientist operates at the intersection of machine learning, experimentation, and business decision-making within one of India’s largest social commerce platforms. The role focuses on building models and analyses that improve trust, discovery, efficiency, and monetization across a highly price-sensitive and diverse user base.
Day to day, the work typically includes:
- Model development and evaluation: designing, training, and validating models for use cases such as recommendations, fraud detection, search relevance, or logistics optimization.
- Experimentation and measurement: running A/B tests, defining success metrics, and interpreting results under real-world noise and constraints.
- End-to-end ownership: taking models from data exploration through deployment, monitoring, and iteration in production.
- Cross-functional collaboration: working closely with product, engineering, and operations teams to translate insights into scalable solutions.
Culturally, Meesho emphasizes ownership, speed, and practical impact. Data scientists are expected to move quickly without sacrificing rigor, make trade-offs explicit, and stay close to business outcomes rather than optimizing models in isolation. Comfort with ambiguity and a bias toward action are consistently valued.
From a growth perspective, the role offers exposure to large-scale marketplace dynamics and production machine learning. As data scientists deepen context across domains, many grow into senior IC roles, technical leadership positions, or broader product-facing analytics roles within the organization.
FAQs
How long does the Meesho data scientist interview process take?
Most candidates complete the Meesho data scientist interview process in four to seven weeks, depending on role seniority and scheduling availability. Early stages such as resume screening and the online assessment usually move quickly, while technical and hiring manager rounds can take longer due to coordination across teams.
How technical is the Meesho data scientist interview?
The interview is highly technical, covering machine learning fundamentals, statistics, coding and DSA, SQL, and system design. However, Meesho does not test theory in isolation; interviewers expect you to explain why you chose a method and how it impacts real business metrics.
Does Meesho focus more on machine learning theory or applied problem-solving?
Meesho strongly emphasizes applied data science. Interviewers care less about perfect model formulations and more about how you frame problems, handle messy data, design experiments, and iterate in production environments tied to business outcomes.
What kind of background does Meesho look for in data scientist candidates?
Meesho hires candidates across experience levels, typically ranging from 1–6+ years, who demonstrate strong fundamentals, ownership, and comfort with ambiguity. Prior experience in marketplaces, recommendations, experimentation, or large-scale behavioral data is helpful but not required.
How should I prepare for machine learning system design questions?
You should practice designing end-to-end ML systems, including data ingestion, feature generation, model selection, evaluation, deployment, and monitoring. Focus on trade-offs such as latency, data quality, cold start, and feedback loops rather than complex architectures alone.
What Meesho Data Scientists Are Really Looking For
Meesho’s data scientist interview is a test of judgment at scale. Interviewers look for candidates who can connect models to business outcomes, reason through imperfect data, and make clear trade-offs when shipping and iterating in production systems that affect millions of users. Strong candidates focus on defining the right metrics, explaining why a model should exist, and knowing when to adjust or roll back based on real-world impact.
Preparing effectively means practicing the way Meesho teams work day to day. Building fundamentals through the data science interview learning path, applying them under pressure with realistic challenges, and refining communication via live mock interviews will help you develop the production-ready thinking Meesho values.
Meesho Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||||||||
Let’s say you work at a file-hosting website. You have information on user’s daily downloads in the Use the window function Example: Input:
Output:
| ||||||||||||||||||||
Data Structures & Algorithms | Hard | |||||||||||||||||||
SQL | Medium | |||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences