
16 Best Fintech Machine Learning Projects with Code (Beginner to Advanced)


Introduction: Building Real-World Skills for Finance and ML Roles
Fintech machine learning projects apply data science techniques to financial problems like fraud detection, credit scoring, and market prediction. These projects matter because they help you build a job-ready portfolio, demonstrate practical skills in interviews, and show you can work with real financial data and constraints.
In this guide, you’ll find fintech ML projects with clear use cases, datasets, and skill focus, which are relevant whether you’re a beginner or preparing for advanced roles.
What You’ll Learn
- How to build fraud detection models using imbalanced datasets
- How to create stock price prediction systems with time series models
- How to develop credit risk and loan default models used in lending
- How to apply NLP for financial sentiment analysis
- How to approach fintech take-home challenges and case studies
- How to choose the best finance project based on your role and skill level
If you’re preparing for interviews, explore our interview guides for finance and ML roles to turn these projects into strong talking points with recruiters.
How to Choose the Right Fintech Machine Learning Project
Choosing the right fintech machine learning project involves aligning the project with your career goal, current skill level, and access to usable financial data. The strongest portfolios are built by selecting projects that mirror real job responsibilities in banking, trading, or fintech product teams.
1. Start with your career goal
Different fintech roles prioritize different types of machine learning work, so your project choice should reflect the direction you are targeting.
- Data science or ML roles: Focus on fraud detection and credit risk modeling projects, since these are commonly tested in fintech interviews and involve classification, imbalance handling, and feature engineering.
- Quantitative finance or trading roles: Prioritize time series forecasting, algorithmic trading, and market prediction projects, where modeling sequences and financial signals is essential.
- Product analytics or fintech product roles: Choose customer segmentation and behavioral analytics projects, where clustering, user insights, and business interpretation are key.
2. Match the project to your skill level
Your technical depth should guide the complexity of the project you select.
| Skill Level | Suitable Fintech ML Project |
|---|---|
| Beginner | Structured datasets, simpler classification tasks, and guided tutorials (regression and basic NLP) |
| Intermediate | Imbalanced datasets, feature engineering-heavy problems, and real-world financial datasets with noise and missing values |
| Advanced | Large-scale datasets, production-style workflows, and models that require optimization, interpretability, and performance tuning. |
3. Check dataset quality and realism
A strong finance machine learning portfolio project is defined by the quality of the data as much as the model itself.
- Prefer datasets that include real financial signals such as transactions, market prices, or customer behavior
- Look for datasets with realistic challenges like class imbalance, time dependency, or missing values
- Ensure the dataset supports end-to-end analysis, from preprocessing to modeling and evaluation
- Avoid overly clean or toy datasets if your goal is interview readiness
Quick Index: Fintech Machine Learning Projects by Skill Level and Type
- Beginner Fintech Machine Learning Projects
- Intermediate Projects (Real-World Modeling)
- Advanced / Production-Level Projects
- Fintech Take-Home Challenges
Beginner Fintech Machine Learning Projects
These beginner fintech machine learning projects focus on core skills like classification, time series basics, and data preprocessing using accessible datasets and guided tutorials. They’re ideal for building a finance ML portfolio without requiring advanced modeling or large-scale data pipelines.
1. Stock Sentiment Analysis
Build a model that predicts stock movements using financial news and sentiment analysis, which is one of the most common NLP-based fintech machine learning projects.
- Skills: NLP, sentiment analysis, feature extraction
- Tools: Python, NLP libraries (e.g., NLTK, TextBlob)
- Dataset: Sentiment Analysis for Financial News dataset
- Get started: Follow this tutorial
- Why it’s useful: Introduces real-world financial text data and signal extraction
2. Predicting Netflix Stock Prices
Learn the fundamentals of time series forecasting in finance by predicting stock prices using historical data and deep learning models.
- Skills: Time series analysis, sequence modeling
- Tools: Python, LSTM/RNN (Keras)
- Dataset: Netflix stock price data from Yahoo! Finance
- Get started: Project tutorial
- Extra resources:
- Why it’s useful: Builds intuition for financial time series and neural networks
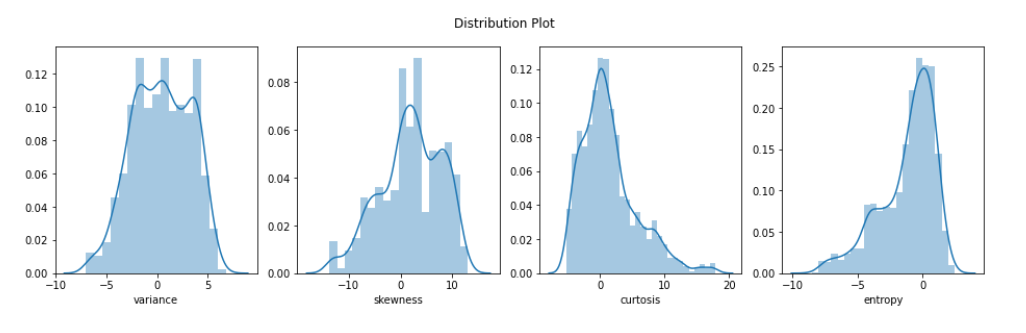
3. Bank Note Authentication Project
This beginner-friendly fraud detection machine learning project uses image data to classify real vs. forged banknotes.
- Skills: Classification, feature engineering
- Tools: Logistic regression, neural networks
- Dataset: Bank Note Authentication Dataset (UCI)
- Get started:
- Bonus dataset: Forgery Image Dataset
- Why it’s useful: Introduces fraud detection concepts with simple, structured data
4. Bank Marketing Campaign
This project analyzes customer data to predict marketing outcomes, making it one of the most practical finance data science projects for beginners. You will predict whether a customer will subscribe to a term deposit using information such as their age, job, marital status, education, and account balance.
- Skills: Data preprocessing, classification, model evaluation
- Tools: Python, scikit-learn
- Dataset: Bank marketing dataset
- Key concepts: Handling categorical variables, class imbalance, evaluation metrics
- Why it’s useful: Mirrors real-world business problems in fintech and banking
Intermediate Projects (Real-World Modeling)
These intermediate fintech machine learning projects focus on real-world financial problems like credit risk, fraud detection, and customer modeling using larger datasets and more advanced techniques. They’re ideal for candidates who already understand ML basics and want to build portfolio projects that reflect production-level financial use cases.
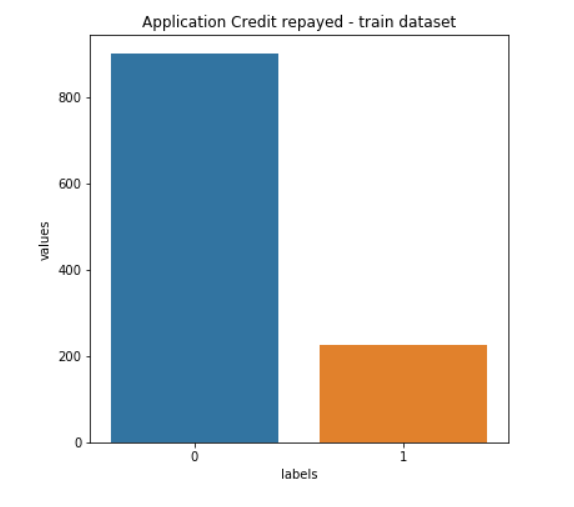
5. Credit Risk Modeling Project
As one of the most common fintech machine learning projects in lending and risk analytics, this entails working with a large-scale dataset to predict loan repayment and default risk.
- Skills: Classification, feature engineering, data cleaning
- Tools: XGBoost, CatBoost, LightGBM
- Dataset: Credit Risk Modeling Kaggle competition
- Alternative dataset: Credit Risk Classification Dataset
- Get started:
- Why it’s useful: Core project for fintech, banking, and ML roles focused on risk modeling
6. Credit Card Fraud Detection Project
In this essential fraud detection machine learning project in finance, you are tasked to detect fraudulent transactions using a highly imbalanced dataset. The dataset includes anonymized features and a target variable indicating fraud.
- Skills: Imbalanced classification, feature engineering, model evaluation
- Tools: Tree-based models, anomaly detection techniques
- Dataset: Credit card fraud dataset
- Key focus: Identifying high-signal features and improving recall/precision tradeoffs
- Why it’s useful: Reflects real-world fraud systems used in payments and fintech
7. Machine Learning Bankruptcy Predictions
You’ll predict company bankruptcy using structured financial data, which is an important classification problem in fintech and risk analysis.
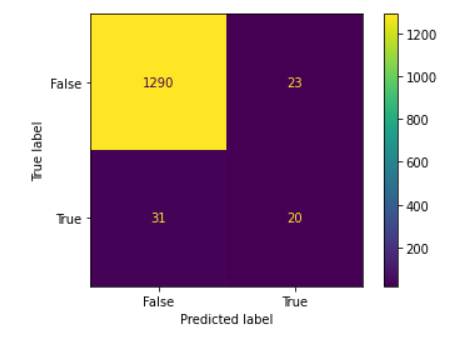
- Skills: EDA, feature selection, classification modeling
- Tools: Support Vector Machines, K-Nearest Neighbors, tree-based models
- Dataset: Company Bankruptcy Prediction Dataset
- Key focus: Understanding financial indicators and their predictive power
- Why it’s useful: Common use case in credit risk, lending, and financial analysis
8. Customer Behavior Analysis
This project focuses on segmentation depth based on customer behavior and demographics, an approach widely used in fintech product analytics and personalization. The dataset includes indicators like purchase type, marital status, age, and educational level to determine spending patterns.
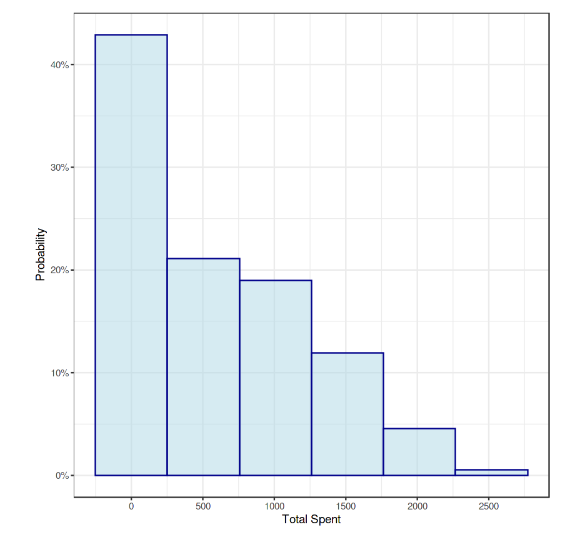
- Skills: Clustering, EDA, feature interpretation
- Tools: K-means, hierarchical clustering
- Dataset: Customer behavior analysis project
- Extra resource: Clustering segmentation tutorial
- Why it’s useful: Helps model user behavior for targeting, retention, and product decisions
9. Customer Valuation Prediction Project
This is an important finance ML project for revenue and personalization modeling, which predicts customer transaction value or lifetime value using regression.
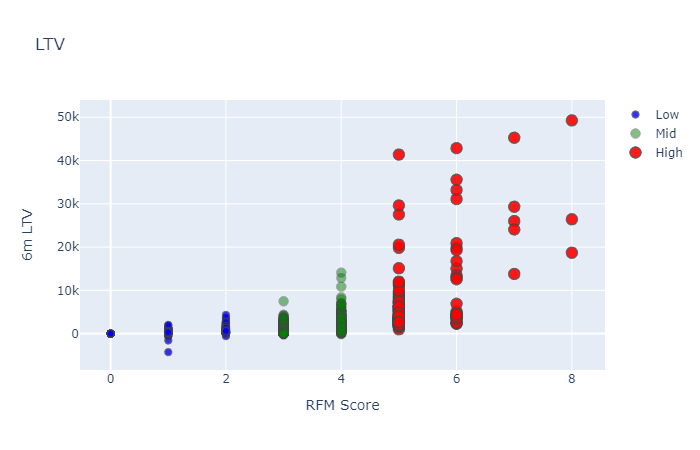
- Skills: Regression modeling, feature engineering, model tuning
- Tools: Linear regression, Ridge/Lasso, KNN regressor
- Dataset: Santander Value Prediction Dataset
- Alternative datasets:
- Why it’s useful: Directly tied to business metrics like revenue forecasting and customer targeting
Advanced / Production-Level Projects
These advanced fintech machine learning projects focus on production-style modeling challenges such as time series forecasting, large-scale fraud detection, and algorithmic trading strategies. They are designed for learners who already understand core ML workflows and want to work with complex financial datasets and real-world constraints.
10. Time Series Stock Predictions in Python
This project introduces time series forecasting in fintech using Facebook Prophet, a widely used model for scalable and interpretable financial predictions. It is commonly used in production environments for quick deployment of forecasting systems. The goal is to predict stock prices using historical market data.
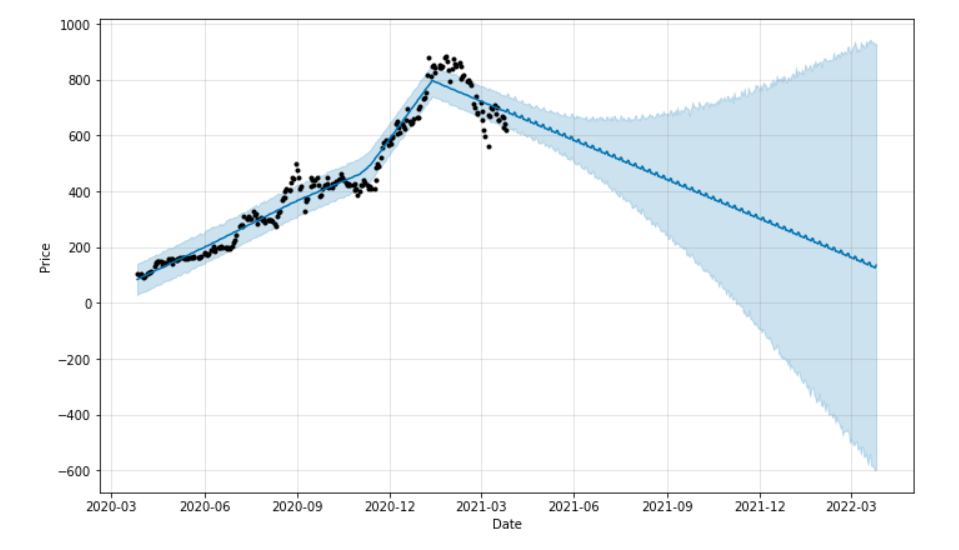
- Skills: Time series analysis, forecasting, feature engineering
- Tools: Facebook Prophet, Python
- Dataset: TESLA stock data
- Get started:
- Why it’s useful: Builds foundational skills in financial forecasting and production-ready time series modeling
11. Fraud Detection on Large-Scale Data (IEEE dataset)
This project focuses on large-scale fraud detection in e-commerce transactions, where class imbalance and feature complexity are key challenges.
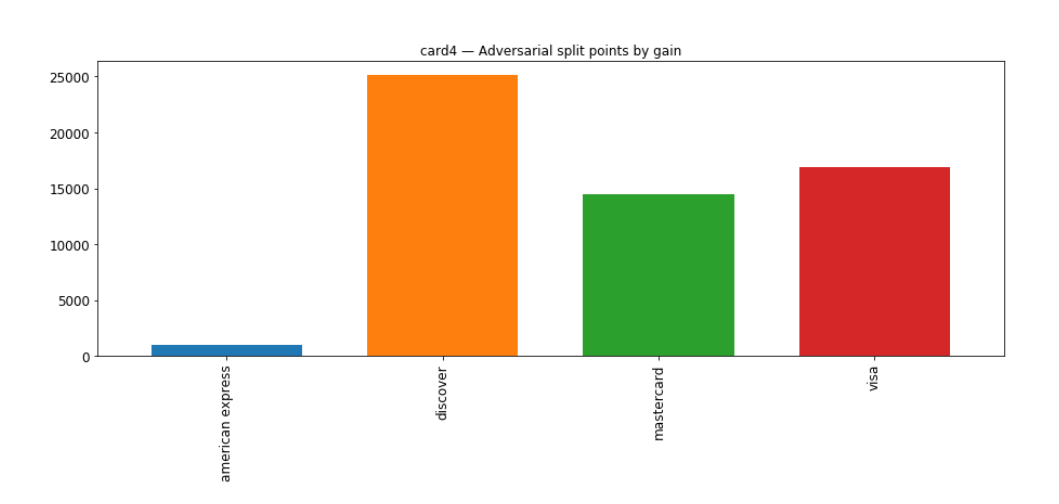
- Skills: Large-scale modeling, feature analysis, imbalanced classification
- Tools: Gradient boosting models, decision trees
- Dataset: IEEE Fraud Detection Challenge
- Key focus: Understanding decision boundaries through split point analysis
- Notebook reference: Decision tree split point analysis
- Why it’s useful: Mirrors real-world fraud detection systems used in fintech and payment platforms
12. Detecting Arbitrage Opportunities in Stocks
This project explores how machine learning can identify arbitrage opportunities in financial markets, where pricing inefficiencies exist between assets or exchanges.
- Skills: Regression modeling, time-series signals, financial feature engineering
- Approaches: Regression models, time-delay neural networks
- Key concept: Arbitrage in financial markets
- Reference methods: Machine learning for statistical arbitrage
- Additional resource: Python packages for algorithmic trading
- Why it’s useful: Introduces quantitative trading strategies and market inefficiency modeling in fintech
Fintech Take-Home Challenges
These fintech data science take-home challenges simulate real interview assignments used by companies in fintech, payments, and data-driven product teams. They are designed to test not just machine learning skills, but also problem framing, communication, and business reasoning, making them ideal practice for real-world interview scenarios.
13. Customer Inquiry Clustering (StepStone)
This take-home focuses on unsupervised learning for customer support and financial inquiry data, where the goal is to group similar loan and product-related requests.

- Company context: StepStone (financial advisory and management firm)
- Core task: Cluster customer inquiries using unsupervised learning
- Skills tested: NLP, clustering, algorithm selection, interpretation
- Key deliverable: Justify clustering approach and explain segment structure
- Why it matters: Mirrors real-world fintech use cases in customer support automation and inquiry routing
14. Cryptocurrency Price Monitoring (Invitae)
This take-home combines data engineering and sentiment analysis to explore how social media signals relate to cryptocurrency price movements.

- Company context: Invitae
- Core task: Analyze correlation between Twitter sentiment and crypto price changes
- Skills tested: Data pipeline design, sentiment analysis, time series correlation
- Key deliverable: Working code or technical design explaining approach
- Why it matters: Reflects real-world fintech problems involving alternative data signals and market behavior
15. Predicting E-Commerce Success (Goodwater Capital)
This take-home focuses on startup success prediction and financial forecasting in e-commerce, using historical data from successful companies.

- Company context: Goodwater Capital (venture capital firm)
- Core task: Identify patterns in successful e-commerce businesses
- Skills tested: Feature engineering, classification thinking, forecasting
- Key deliverable: Business insights on “winning” companies + 12-month sales forecast for Brandless
- Why it matters: Common VC-style data science task used for investment decision support
16. Analyzing Fintech Product Performance (Stripe)
This take-home simulates a product analytics and business intelligence task for a fintech company by asking you to take a flagship product dataset and present your analysis of the performance.

- Company context: Stripe
- Core task: Analyze product usage and customer segmentation performance
- Skills tested: Data analysis, product analytics, storytelling, prioritization
- Key deliverable: Short presentation with insights and recommendations
- Guiding questions:
- How are Stripe products and segments performing?
- What deeper analysis would you explore with more data?
- How would you prioritize product investment decisions?
- Why it matters: Reflects real fintech product analytics and decision-making workflows in SaaS/payment platforms
Frequently Asked Questions (FAQs)
What are the best fintech machine learning projects for beginners?
The best beginner fintech machine learning projects are those that focus on structured data and standard modeling tasks like classification and regression. Common starting points include fraud detection, credit risk modeling, stock sentiment analysis, and customer behavior analysis. These projects help you build foundational skills in data preprocessing, feature engineering, and basic model evaluation. They are also widely recognized in interviews, making them strong portfolio additions.
How do fintech ML projects help in job interviews?
Fintech ML projects are often used as discussion points in data science and machine learning interviews because they reflect real industry problems. Interviewers typically look for how you frame the problem, handle data challenges, and explain model decisions. Projects like credit risk or fraud detection demonstrate your ability to work with imbalanced datasets and business constraints.
What skills are most important for fintech machine learning projects?
The most important skills include Python, SQL, and core machine learning techniques such as classification, regression, and clustering. In fintech specifically, you also need to understand time series analysis, handling imbalanced datasets, and feature engineering for financial data. Communication is equally important because many fintech projects require translating model outputs into production-ready insights.
How do I make a fintech ML project stand out in my portfolio?
To make a fintech ML project stand out, you need to go beyond just building a model. Focus on explaining the business problem clearly, handling real-world data issues like missing values or imbalance, and evaluating models using meaningful metrics. Adding interpretability techniques such as feature importance or SHAP values also helps.
Do I need advanced math for fintech machine learning projects?
You do not need advanced mathematics to start most fintech ML projects. A solid understanding of probability, basic statistics, and linear algebra is enough for beginner and intermediate projects. More advanced roles, such as quantitative trading or algorithmic finance, may require deeper knowledge of stochastic processes or optimization. However, most interview-focused projects prioritize implementation, interpretation, and problem-solving over theoretical math.
What datasets are commonly used in fintech machine learning projects?
Common datasets include credit risk data, stock market historical prices, fraud detection datasets, and customer transaction records. Platforms like Kaggle and UCI Machine Learning Repository provide many of these datasets. In fintech specifically, datasets often involve imbalanced classes or time-based data, which adds realism.
Conclusion: Build Fintech ML Projects that Stand Out
Fintech machine learning projects are one of the most effective ways to demonstrate applied skills in data science, especially for roles in banking, payments, and financial technology. Whether you are working on credit risk modeling, fraud detection systems, or customer segmentation, what makes it stand out is not just the model itself, but how well you connect the technical work to financial decision-making.
To further strengthen your skills and prepare for fintech ML roles, you can explore structured learning paths and practice resources from Interview Query:
- Build foundational programming skills with the 14 Days of Python study plan
- Strengthen applied modeling knowledge through the Modeling & Machine Learning learning path
- Practice realistic fintech scenarios and case studies using the question bank
Ultimately, the strongest fintech ML portfolios are built by combining practical projects with consistent interview preparation. With the right mix of projects, problem-solving ability, and communication skills, you can position yourself effectively for machine learning and data science roles in fintech.