Scaling Data Science Requires Better Data Labeling


Quality Data Labeling Is a Necessity
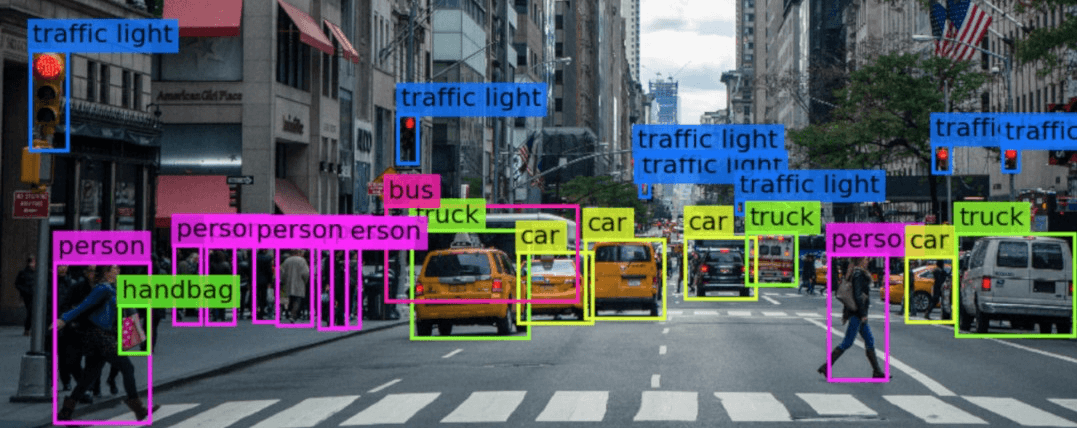
Did you ever wonder how a self-driving car works? How the car knows the difference between a red or green light, a barrier or dotted lines, and a human or street cone?
What happens is that the computer in the car gets trained on imaging data. And if you’re building a self-driving car startup, you would probably need a lot of data points. One way to do it would be to start out with one car, have someone drive it around the city for a few months, and when they come back, you realize that to build your tech, you’ll probably need over a few million labeled images of the road.
So now, what do you do? Do you start hiring college interns and data labelers like crazy? Do you outsource it to another company that touts better quality data labeling?
And an even better question – how do you even verify that your data labels are good?
How to Label 1 Million Data Points a Week
As it turns out, one of the biggest limitations of data science is actually in operations. Most of our AI models and systems are inherently tied to the quality and speed of our data labeling done by human “expert labelers”.
Companies like Scale.ai will pop up as a business when they realize they can promise not only higher quality labels, but also faster turnaround times. Here’s an article on how Scale got to the point where they could start labeling 1 million data points every week for their clients.
In their blog post, they tap into what I call “operational efficiency”. By first doing assessments to understand who the “best labelers” are, those best labelers set benchmarks for quality levels. Subsequent new hires are then benchmarked against the best labelers, determined by auditing some sample size.
For example, let’s say a new labeler rates 1,000 images. An expert labeler would then look at a sample size of 100 images to determine “true” correctness. If it’s within a certain standard of error, they then effectively gain more confidence in their labeling ability.
Quality Control: Interpreting “True Correctness”
One thing to note is that true correctness is hard to interpret. In this scenario, Scale, or any other company that has to outsource labeling, has to have a number of expert labelers that understand how to adapt to any industry’s labeling constraints.
For example, the Department of Defense currently has an active data science contest to build a computer vision model to identify illegal fishing from satellite photos offshore.
If you’re the DOD, you have to hire someone, likely an “illegal fishing detective from the sky,” to actually look at satellite images all day and determine which boats are legitimate and which ones are hauling more than their share of salmon.
If you’re a smart client, you have a cost per image or data point that you need labeled, and that cost is calculated most likely by taking the budget and dividing it by the number of labelers you need. But of course, if you’re a new smart driving startup, the profits in the future world are fat and juicy, so you’ll pay a lot for those data points.
The Future of Data Labeling
This rat race is now getting bigger and bigger. The optimizations around data labeling are getting more and more important. Companies, including SuperAnnotate, are sprouting up to make the data labeling process itself more efficient. If a model can help a labeler make better decisions or increase speed, then even that in itself is an edge.
The funny part is, in the future, you can imagine that Scale will be able to build models on all of the data they previously helped label to give some of their clients better data faster than the company can even label data sometimes. If I could build a model using just a sample of their labeled data that eventually becomes more accurate than the best expert labeler for the client’s company, then Scale has already automated out the use for labelers to begin with.