Baidu Interview Questions


Published March 27, 2026
Estimated reading time: 5 minutes
Baidu Interview Guides
Click or hover over a slice to explore questions for that topic.
Data Structures & Algorithms
(1)
Baidu Interview Questions
Practice for the Baidu interview with these recently asked interview questions.
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Medium | |
Binary Tree ValidationYou are given the root of a binary tree. You need to determine if it is a valid binary search tree (BST). A valid BST is defined as follows:
Given the function Example:Input:
Output: | ||
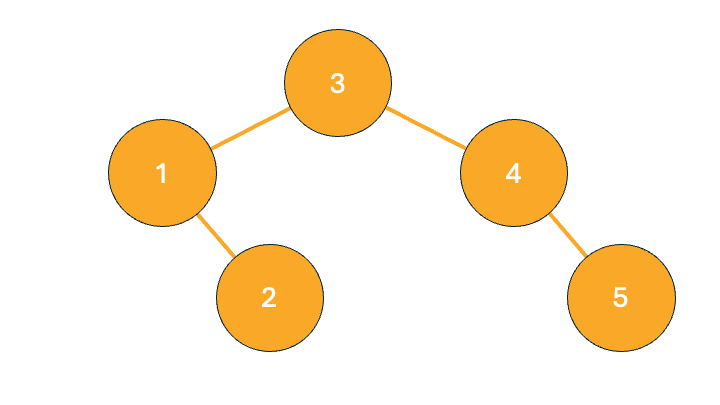 Converted Binary Tree.png
Converted Binary Tree.pngLoading pricing options
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Challenge
Check your skills...
How prepared are you for working at Baidu?
Baidu Salaries by Position
Most data science positions fall under different position titles depending on the actual role.
From the graph we can see that on average the Data Scientist role pays the most with a $167,900 base salary while the Business Analyst role on average pays the least with a $73,848 base salary.
Discussion & Interview Experiences