Top 27 Pandas Interview Questions with Answers for 2025


Overview
Pandas is a powerful Python library for data manipulation, cleaning, and preparation. Its standout feature is the DataFrame, a versatile 2-dimensional data structure that excels at handling tabular data.
Pandas’ seamless interoperability with various data formats, such as CSVs, Excel sheets, and SQL databases, has made it an essential tool for data analysts and scientists. By leveraging its rich functionalities, professionals can efficiently work with diverse datasets and unlock valuable insights.
In this article, we cover essential pandas interview questions to test your knowledge of data manipulation, DataFrames, and key functionalities for data science.
Which Job Titles Often Encounter Pandas Interview Questions?
Pandas, the go-to Python library for manipulating data in tabular format, is commonly encountered in various data management job roles whether handling SQL relations, CSVs, sheets, or schema-less data file formats like JSON, Pandas offers the flexibility required for working with diverse datasets.
The following job titles frequently encounter Pandas as an interview question or a required skill:
- Data Engineer
- Data Scientist
- Data Analyst
- Business Intelligence Consultant
- Python Software Engineer
- Machine Learning Engineer
How Important are Pandas in Data Science?
Pandas are vital tools for data scientists. They serve as versatile Swiss army knives for tasks like data cleaning, manipulation, and analysis. Pandas seamlessly integrate with other data science libraries like Matplotlib and NumPy.
Pandas are a fundamental tool for data science. They benefit from operating within the Python environment, which allows for easy automation and integration with other modules.
Speed is another standout feature of Pandas. Implementing in a language other than Python, it outperforms Python primitive lists, enabling faster data processing.
While Pandas is undoubtedly a powerful tool, its effectiveness ultimately relies on the data scientist’s proficiency in utilizing it appropriately.
In this article, we will use Jupyter Notebook to explore data. If you don’t have it installed on your workstation, Feel free to download Jupyter.
Beginner Pandas Interview Questions
1. What is Pandas?
Pandas is a Python library designed for connecting .csv, .xlsx, and other tabular-oriented data sources to Python, allowing you to create scripts that can help modify the data through a data structure called a DataFrame.
2. What Data Structures are primarily associated with Pandas, and how do they work?
The Pandas library concerns itself with two primary data structures: the DataFrame and the series.
- The DataFrame is a two-dimensional, mutable data structure with rows and columns as its axes. As mentioned earlier, Pandas’ DataFrame handles multiple data types, and each block (also referred to as a cell in a sheet) is identified through an index (specified as a keyword argument) and column labels.
- Meanwhile, the series is the one-dimensional counterpart to the DataFrame, ergo a vector.
3. What are the key features of Pandas?
Pandas is a powerful library with several key features, making it a popular choice for data analysis and manipulation tasks. Let’s explore some of its notable features:
- Integration with NumPy: Pandas seamlessly integrates with NumPy, allowing for efficient handling of large datasets and enabling the use of NumPy’s mathematical functions on Pandas objects.
- Tabular Data Presentation: Pandas excels in handling tabular data, such as spreadsheet-like structures or SQL tables.
- Reshaping of Tabular Data: Pandas offers powerful, allowing you to pivot, stack, and melt data, making it easier to transform and restructure datasets to suit your analysis requirements.
- Time Series Support: Pandas provides dedicated functions and data structures for working with time series data. It offers various features for time-based indexing, resampling, frequency conversion, and time zone handling, simplifying time series analysis tasks.
- Missing Data Handling: Pandas provides methods for handling missing data, such as filling missing values with appropriate estimations or performing operations while ignoring missing entries.
- Data Analysis: Pandas offers efficient functions for analyzing data, allowing you to summarize and compute statistics on subsets of your dataset quickly.
4. How do you import a file from your computer to Pandas?
One of the most significant features of Pandas is the ability to equate a dataframe variable to an entire .csv, .sql, and other tabular data files. How can you achieve this exactly? The general syntax is typically similar to the following:
import pandas as pd
df = pd.read_<data_format>('path')
#replace <data_format> with csv, sql, etc.
For example, let’s look at an example where we are reading a .csv file:
import pandas as pd
df = pd.read_csv('data/test.csv')
5. How do you print and access the information inside the DataFrame?
Building on the earlier code, you can print the dataframe to the console using Python’s built-in print() function. Simply pass the dataframe as a parameter, and it should show you a tabular view of the frame. However, there are ways to manipulate the function’s behavior.
Using df.head() in Pandas
The head() function in Pandas is a useful method to quickly examine the first few rows of a DataFrame. By default, it returns the first 5 rows of the DataFrame. Let’s take a look at the following code example:
import pandas as pd
# Assuming 'df' is your DataFrame
head = df.head(n)
head
# you can also do a more conventional print(head), but Jupyter Notebook automatically
# prints a variable if its the only token in a line.
In the code snippet above, we use the head() function on the DataFrame df. By passing the argument n, you can specify the number of rows you want to retrieve. If no argument is provided, Pandas assumes a default value of 5.
Similarly, if you want to access the last few rows of the DataFrame, you can use the tail() function. It works in a similar way to head(), but returns the last few rows of the DataFrame instead.
? Quick tip: Using head() and tail() is a convenient way to get a quick overview of the data contained in a DataFrame without displaying the entire dataset. It’s especially useful when dealing with large datasets or when you want to glimpse the structure and values at the beginning or end of the DataFrame.
Accessing specific elements in a DataFrame
We can utilize several methods to access the elements inside a DataFrame. One of the easiest examples is using the ‘at’ attribute of a DataFrame. For example, let’s declare a DataFrame with the following contents.
df = pd.DataFrame({'Names' : ['Joanna', 'Khent', 'Jeastel'],
'Positions' : ['Lead', 'Public Relations', 'Volunteer'], 'Age' : [22, 21, 20]
, index=[0, 3, 15]}
Notice that we also specified the keyword argument index= to specify how these values are indexed inside a DataFrame. Suppose that we are to print out the DataFrame. It would look similar to the following table:
| Names | Positions | Age | |
|---|---|---|---|
| 0 | Joanna | Lead | 22 |
| 3 | Khent | Public Relations | 21 |
| 15 | Jeastel | Volunteer | 20 |
Now, if we were to access the value ‘volunteer,’ you would need to do the following:
df.at[15, 'Positions']
6. Practical Question: Book Availability Update
The category for this question is: Pandas Update of CRUD
Let’s start our first practical question session with something easy and try to execute one of the basic CRUD operations: update.
As an experienced librarian proficient in Python, you aim to optimize the process of checking the availability of book copies.
Write a function update_availability( that takes a dataframe, a book id, and a number of copies as input. This function should update the copies_available value for the specified book_id in the dataframe and return the updated dataframe.
Note: The book_id corresponds to the index in the dataframe. If the book_id is not found, the function should return the original dataframe without any changes.
Example:
Input:
| book_id | book_title | copies_available |
|---|---|---|
| 0 | Moby Dick | 5 |
| 1 | 1984 | 7 |
| 2 | To Kill a Mockingbird | 3 |
| 3 | The Great Gatsby | 2 |
| 4 | Pride and Prejudice | 10 |
Output:
update_availability(book_id: int, copies: int, df_books: pd.DataFrame) ->
| book_id | book_title | copies_available |
|---|---|---|
| 0 | Moby Dick | 5 |
| 1 | 1984 | 7 |
| 2 | To Kill a Mockingbird | 3 |
| 3 | The Great Gatsby | 8 |
| 4 | Pride and Prejudice | 10 |
Solution
def update_availability(book_id: int, copies: int, df_books: pd.DataFrame) -> pd.DataFrame:
if book_id in df_books.index:
df_books.at[book_id, 'copies_available'] = copies
return df_books
The function update_availability takes three parameters: book_id, which is the ID of the book we want to update; copies, which is the new number of copies available for that book; and df_books, which is the DataFrame holding the book information.
Inside the function, we first check if the book_id exists in the DataFrame’s index using the in keyword
if book_id in df_books.index:
If the book_id is present in the DataFrame, we update the value of copies_available for that book using the pd.at function.
df_books.at[book_id, 'copies_available'] = copies
The pd.at function allows us to modify a single value in the DataFrame, specified by its row and column labels.
Finally, we return the updated DataFrame, regardless of whether the book ID was found or not:
return df_books
7. How can you perform basic filtering with Pandas?
Boolean Indexing
Boolean indexing in Pandas allows you to filter a DataFrame based on a Boolean condition. It provides flexibility and readability in constructing complex conditions using logical operators (& for AND, | for OR, ~ for NOT) and parentheses. Here’s an example:
filtered_df = df[(df['Age'] > 25) & (df['Gender'] == 'M')
This query retrieves rows where the ‘Age’ > 25 and the Gender is ‘M’.
Query Method
The query() method in Pandas provides a simplified syntax for filtering a DataFrame. It lets you write conditions directly as strings without explicitly referencing the DataFrame or columns. Here’s an example:
filtered_df = df.query("Age > 25 and Gender == 'M'")
Both Boolean indexing and the query() method are effective ways to perform basic filtering in Pandas. The choice between them depends on your preference and the complexity of the filtering conditions you must apply.
? Quick tip: The query method uses python’s syntax.
8. Practical Question: Good Grades and Favorite Colors
The category for this question is: Pandas filtering*
You’re given a DataFrame of students named students_df:
students_df table
| name | age | favorite_color | grade |
|---|---|---|---|
| Tim Voss | 19 | red | 91 |
| Nicole Johnson | 20 | yellow | 95 |
| Elsa Williams | 21 | green | 82 |
| John James | 20 | blue | 75 |
| Catherine Jones | 23 | green | 93 |
Write a function named grades_colors to select only the rows where the student’s favorite color is green or red, and their grade is above 90.
Example:
Input:
import pandas as pd
students = {"name" : ["Tim Voss", "Nicole Johnson", "Elsa Williams", "John James", "Catherine Jones"], "age" : [19, 20, 21, 20, 23], "favorite_color" : ["red", "yellow", "green", "blue", "green"], "grade" : [91, 95, 82, 75, 93]}
students_df = pd.DataFrame(students)
Output:
def grades_colors(students_df) ->
| name | age | favorite_color | grade |
|---|---|---|---|
| Tim Voss | 19 | red | 91 |
| Catherine Jones | 23 | green | 93 |
Solution
This question requires us to filter a data frame by two conditions: the student’s grade and favorite color.
Let’s start by filtering by grade since it’s a bit simpler than filtering by strings. We can filter columns in pandas by setting our data frame equal to itself with the filter in place.
In this case:
df_students = df_students[df_students["grade"] > 90]
If we were to look at our data frame after passing that line of code, we’d see that every student with a lower grade than 90 no longer appears in it.
Now, we need to filter by favorite color. but we want to choose between two colors red and green. We will use isin() method that will compare the color cell with a list of colors passed to it, in this case, will be ['red','green']
df_students = df_students[df_students["grade"] > 90]
If we were to look at our data frame after passing that line of code, we’d see that every student with a lower grade than 90 no longer appears in it.
Now, we need to filter by favorite color. but we want to choose between two colors red and green. We will use isin() method that will compare the color cell with a list of colors passed to it, in this case, will be ['red','green']
students_df = students_df['favorite_color'].isin(['red','green'])
Finally, we can use the & operator to combine the two conditions’ gradeandcolor` to filter to rows.
Our syntax should look like this:
import pandas as pd
def grades_colors(students_df):
students_df = students_df[(students_df['grade'] > 90) &
students_df['favorite_color'].isin(['red','green'])]
return students_df
9. Repeated Category Purchase
You’re analyzing a user’s purchases for a retail business.
Each product belongs to a category. Your task is to identify which purchases represent the first time the user has bought a product from its own category and which purchases represent repeat purchases within the product category.
Your code should output a table that includes every purchase the user has made. Additionally, the table should include a boolean column with a value of 1 if the user has previously purchased a product from its category and 0 if it’s their first time buying it.
Note: Sort the results by the time purchased, in ascending order.
Solution
Within the CTE row_nums, we use the row_number() window function to count products within a category. Since id is the primary key, values are unique. Therefore, the rank() function also could have been applied to sort.
We know that the products ranked 1st within a category are not previously purchased, so we may apply the if () function to categorize products as 0 or 1.
Intermediate Pandas Interview Questions
10. What is the difference between merge and concatenate in Pandas?
Merge and concatenate are the most commonly used functions when fusing two datasets (a series or a DataFrame). Though they may seem the same, along with join() and append(), they all serve different purposes.
Merge is utilized for general use compared to concatenate. When two datasets share information, merging is the best option.
Merge has two required parameters, the left and right datasets, and four variants: inner merge, outer merge, left merge, and right merge.
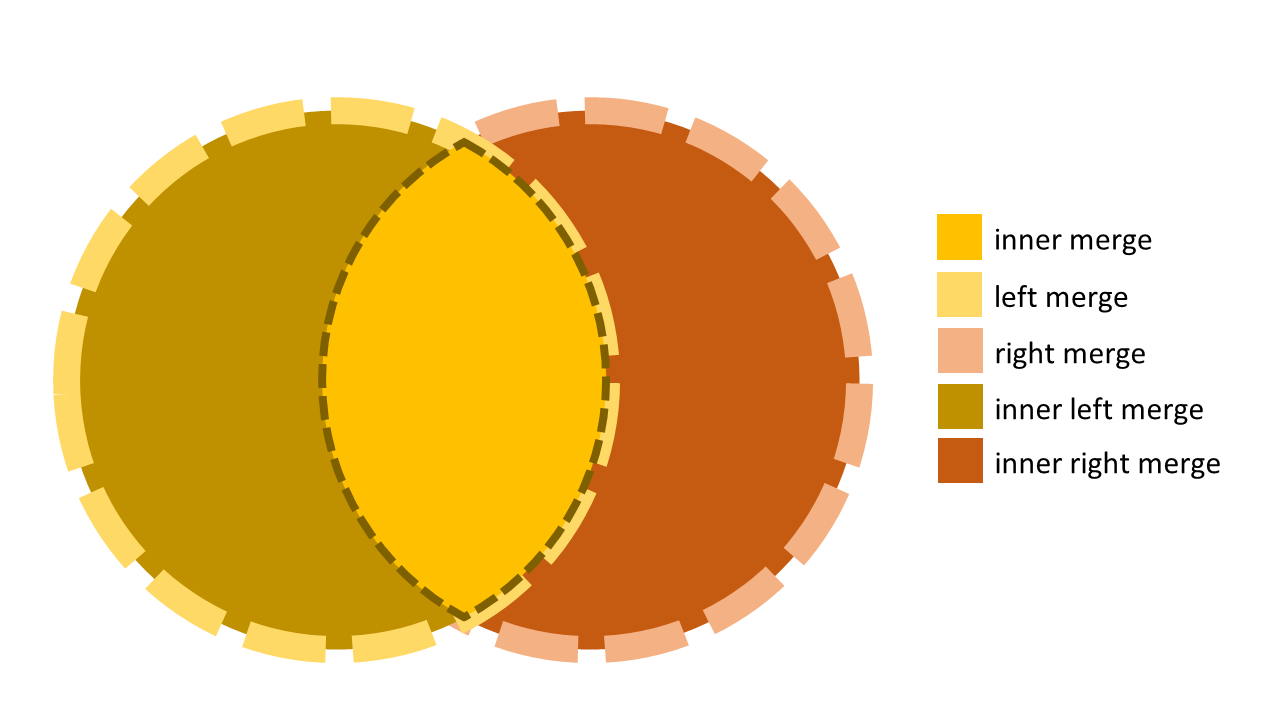 Merge variants, visualized
Merge variants, visualized
The inner merges (including the left and right) put you at risk of losing data upon merging. However, the outer merge includes all data from both datasets. Let’s look at the following dataframes:
df_one:
| Segment | Answer | |
|---|---|---|
| 0 | Mobile | |
| 1 | Web | |
| 2 | University | Snapchat |
df_two:
| Count | Answer | |
|---|---|---|
| 0 | 2559 | |
| 1 | 32 | |
| 2 | 0 | Snapchat |
You can use the following code to merge:
merged = pd.merge(df_one, df_two)
Which will give you:
| Segment | Answer | Count | |
|---|---|---|---|
| 0 | Mobile | 2559 | |
| 1 | Web | 32 | |
| 2 | University | Snapchat | 0 |
As you can see, Pandas automatically merges rows and columns with the same value. However, using concatenate instead of merging datasets containing columns of the same value and name will automatically stitch the two rows together.
? Quick tip: You can specify the merge condition with the on parameter. For example: pd.merge(df_one, df_two, on='Answer'). This will then base the merge result on the ‘Answer’ column, where the df_one. Answer = df_two. Answer.
Using the following code:
conc = pd.concat([df_one, df_two], axis="columns")
You will get the following result:
| Segment | Answer | Count | Answer | |
|---|---|---|---|---|
| 0 | Mobile | 2559 | ||
| 1 | Web | 32 | ||
| 2 | University | Snapchat | 0 | Snapchat |
Even though the values of the ‘Answer’ columns are the same, they are added twice to the resulting dataset, as concatenate does not check for any matching data.
11. Practical Question: Complete Addresses
The category for this question is: Pandas Merge*
You’re given two DataFrames. One contains information about addresses, and the other contains relationships between various cities and states:
Example:
df_addresses
| address |
|---|
| 4860 Sunset Boulevard, San Francisco, 94105 |
| 3055 Paradise Lane, Salt Lake City, 84103 |
| 682 Main Street, Detroit, 48204 |
| 9001 Cascade Road, Kansas City, 64102 |
| 5853 Leon Street, Tampa, 33605 |
df_cities
| city | state |
|---|---|
| Salt Lake City | Utah |
| Kansas City | Missouri |
| Detroit | Michigan |
| Tampa | Florida |
| San Francisco | California |
Write a function complete_address to create a single dataframe with complete addresses in the format of street, city, state, zip code.
Input:
import pandas as pd
addresses = {"address": ["4860 Sunset Boulevard, San Francisco, 94105", "3055 Paradise Lane, Salt Lake City, 84103", "682 Main Street, Detroit, 48204", "9001 Cascade Road, Kansas City, 64102", "5853 Leon Street, Tampa, 33605"]}
cities = {"city": ["Salt Lake City", "Kansas City", "Detroit", "Tampa", "San Francisco"], "state": ["Utah", "Missouri", "Michigan", "Florida", "California"]}
df_addresses = pd.DataFrame(addresses)
df_cities = pd.DataFrame(cities)
Output:
def complete_address(df_addresses,df_cities) ->
| address |
|---|
| 4860 Sunset Boulevard, San Francisco, California, 94105 |
| 3055 Paradise Lane, Salt Lake City, Utah, 84103 |
| 682 Main Street, Detroit, Michigan, 48204 |
| 9001 Cascade Road, Kansas City, Missouri, 64102 |
| 5853 Leon Street, Tampa, Florida, 33605 |
Solution
In this question, we’re given a dataframe full of addresses (in the form of strings) and asked to interpolate state names (more strings) into those addresses.
We’ll need to match our state names with the cities they contain. That’s going to require us to perform a simple merge of our two dataframes. But before we can do that, we need to split df_addresses so that we can isolate the city part of the address to use in our merge.
We will use a string method, split, on the address field to accomplish this. Since a comma separates the different parts of our address, we can use ', ' as our delimiter to split the string. Because our string is in a dataframe, we can use the expand=Trueargument in our string method to separate the different parts of our address string into different columns in the dataframe.
df_addresses[['street', 'city', 'zipcode']] = df_addresses['address'].str.split(', ', expand=True)
This will give us a dataframe with four columns: address, street, city, and zip code. You may want to remove the address field to keep your dataframe tidy, but it’s not strictly necessary at this juncture.
Now that we have the different parts of our address in separate labeled columns, we can perform our desired merge. Since the city fields of our respective dataframes are identical, we can merge on=“city”.
df_addresses = df_addresses.merge(df_cities, on="city")
Now, we have all of the desired elements of our final address in a single dataframe, but we want to join them all in order into a single string in the address field. To accomplish this, we can use the .agg method with the .join argument to concatenate the different columns we want in our final field. Note that you could also concatenate using + to combine each string, but we’ve chosen the .agg method for efficiency’s sake.
When you’re using the .agg method, you’ll want to establish the order of your final string by calling the column names of your dataframe in the order they’re meant to be joined:
df_addresses['address'] = df_addresses[['street', 'city', 'state', 'zipcode']].agg(', '.join, axis=1)
? Quick tip: the axis=1 argument in the above code merely establishes that we’re aggregating the columns, not the rows, of the DataFrame. axis=0 indicates that we’re aggregating the data vertically. Conversely, axis=1 would imply that we’re aggregating horizontally.
Finally, because our final DataFrame will only have an address field (now complete), we’ll want to remove the street, city, state, and zip code fields.
So, in total, our code looks like:
def complete_address(df_addresses, df_cities):
df_addresses[['street', 'city', 'zipcode']] = df_addresses['address'].str.split(', ', expand=True)
df_addresses = df_addresses.drop(['address'], axis=1)
df_addresses = df_addresses.merge(df_cities, on="city")
df_addresses['address'] = df_addresses[['street', 'city', 'state', 'zipcode']].agg(', '.join, axis=1)
df_addresses = df_addresses.drop(['street', 'city', 'state', 'zipcode'], axis=1)
return df_addresses
12. How do you select specific data types to include or exclude in your DataFrame?
For Pandas, one function helps you include or exclude specific data types into a DataFrame.
The select_dtypes() function can help you include or exclude specific elements based on whether they are of the specified function inside the parameter.
Let’s consider the following DataFrame as an example:
| Name | Age | Height | Weight | Salary |
|---|---|---|---|---|
| John Doe | 32 | 170.2 | 70.1 | 56000 |
| Jane Doe | 28 | 165.1 | 60.5 | 62000 |
| Mike Roe | 45 | 175.3 | 85.6 | 75000 |
| Sarah Poe | 37 | 160.6 | 58.2 | 69000 |
Assume that the age, height, and weight are in integer, float, and float data types, respectively, and the salary is in an integer data type.
The DataFrame in Python:
import pandas as pd
data = {
'Name': ['John Doe', 'Jane Doe', 'Mike Roe', 'Sarah Poe'],
'Age': [32, 28, 45, 37],
'Height': [170.2, 165.1, 175.3, 160.6],
'Weight': [70.1, 60.5, 85.6, 58.2],
'Salary': [56000, 62000, 75000, 69000]
}
df = pd.DataFrame(data)
To select only columns with data types of integer and float:
df.select_dtypes(include=['int', 'float'])
To exclude columns with the string data type:
df.select_dtypes(exclude=['object'])
The include and exclude parameters can be strings or lists. If not specified, all data types will be included.
By utilizing these functions, you can focus on the specific types of data you want to analyze and ignore the rest. For instance, if you’re doing numerical analysis, you might want to exclude string data types. On the other hand, if you’re doing text analysis, you might want to include only string data types.
13. What is a pivot table? How do you create one?
A pivot table in Pandas is a valuable tool for summarizing and aggregating data. To create one, use the pivot() function to help reshape and aggregate data into a compact form.
In pandas, a pivot table summarizes and aggregates data in a tabular format. It allows you to reorganize and transform data, making it easier to analyze and derive insights.
A pivot table takes a DataFrame as input and performs the following operations:
- Grouping: It groups the data based on one or more columns, known as the “index” or “row” values.
- Aggregating: It applies an aggregation function to calculate summary statistics on a specific column or set of columns. The aggregation function can be sum, mean, count, min, max, etc.
- Reshaping: It reshapes the data by creating a new table with the grouped values as rows and columns.
The resulting pivot table provides a compact representation of the data, allowing you to analyze and compare the values based on different dimensions. It helps in summarizing large datasets, identifying patterns, and gaining insights from the data.
Let’s look at examples to illustrate its functionality. Let’s consider the following DataFrame:
| ID | Segment | Age | Revenue |
|---|---|---|---|
| 1 | Segment A | 32 | 50,000 |
| 2 | Segment B | 24 | 36,000 |
| 3 | Segment A | 45 | 80,000 |
| 4 | Segment C | 37 | 75,000 |
| 5 | Segment B | 29 | 46,000 |
A pivot table can be created to summarize the mean revenue by segment as follows:
pivot_df = df.pivot_table(values='Revenue', index='Segment', aggfunc='mean')
This will create a pivot table like:
| Segment | Revenue |
|---|---|
| Segment A | 65,000 |
| Segment B | 41,000 |
| Segment C | 75,000 |
In this example, the values parameter is set to 'Revenue', the column we want to summarize. The index parameter is set to 'Segment', the column we want to group by. The aggfunc parameter is set to 'mean', which specifies that we want to compute the mean revenue for each segment.
The pivot table thus gives us a succinct summary of the mean revenue earned from each segment.
Pivot tables can be a great tool for summarizing and interpreting data, especially when dealing with large datasets that contain many variables. By aggregating the data meaningfully, they can provide valuable insights that might be difficult to obtain otherwise.
14. Practical Question: Branch Sales Pivot
The category of this question is: pivot tables
Your company, a multinational retail corporation, has been storing sales data from various branches worldwide in separate tables according to the year the sales were made. The current data structure is becoming inefficient for business analytics, and management has requested your expertise to streamline the data.
Write a query to create a pivot table showing each branch’s total sales by year.
Note: Assume that the sales are represented by the total_sales column and are in USD. Each branch is represented by its unique branch_id.
Example:
Input:
For simplicity, consider two years: 2021 and 2022.
sales_2021 table
| Column | Type |
|---|---|
| id | INTEGER |
| branch_id | INTEGER |
| total_sales | INTEGER |
sales_2022 table
| Column | Type |
|---|---|
| id | INTEGER |
| branch_id | INTEGER |
| total_sales | INTEGER |
Output:
sales_pivot table
| Column | Type |
|---|---|
| branch_id | INTEGER |
| total_sales_2021 | INTEGER |
| total_sales_2022 | INTEGER |
This output pivot table shows the total sales for each branch, broken down by year.
Solution
import pandas as pd
def branch_sales_pivot(sales_2021: pd.DataFrame, sales_2022: pd.DataFrame) -> pd.DataFrame:
# Assign year to each sales data
sales_2021['year'] = 2021
sales_2022['year'] = 2022
# Concatenate both sales DataFrames
total_sales = pd.concat([sales_2021, sales_2022])
# Group by branch_id and year, summing total_sales, and reset index
total_sales_grouped = total_sales.groupby(['branch_id', 'year'])['total_sales'].sum().reset_index()
# Pivot the DataFrame with branch_id as index, year as columns and total_sales as values
sales_pivot = total_sales_grouped.pivot(index='branch_id', columns='year', values='total_sales')
# Rename columns for clarity
sales_pivot.columns = [f'total_sales_{col}' for col in sales_pivot.columns]
# Fill NA values with 0 (assuming no sales is equal to 0)
sales_pivot.fillna(0, inplace=True)
# Reset index to make branch_id a column again
sales_pivot.reset_index(inplace=True)
return sales_pivot
Inside this function, we first assign a new column called ‘year’ to both sales_2021 and sales_2022 DataFrames. This column helps us track the year the sales data comes from. We set the value of this column to 2021 and 2022 in sales_2021 and sales_2022 DataFrames, respectively.
Next, we combine the two DataFrames into one using the pandas concat function. This function essentially stacks the DataFrames on top of each other, giving us a single DataFrame with sales data from both years.
Once we have all the sales data in a single DataFrame, we perform a group by operation on ‘branch_id’ and ‘year’, calculating each group’s sum of ‘total_sales’. This is achieved using the groupby function in pandas. We then reset the index of the grouped DataFrame to flatten the structure.
Subsequently, we reshape this DataFrame into a pivot table using the pivot function. Here, ‘branch_id’ becomes the index of the pivot table, ‘year’ becomes the columns and the ‘total_sales’ forms the values inside the table. Now, each row represents a branch and each column represents the total sales of that branch for a specific year.
To make our pivot table more understandable, we rename the columns to include the year in the name. This is achieved using a list comprehension that prefixes ‘total_sales_’ to every column name.
There might be cases where a branch did not make any sales in a particular year. For such cases, the pivot function will fill the cell with a NA value. We replace these NA values with 0 using the fillna function under the assumption that no sales equals 0 sales.
Lastly, we reset the pivot table index to make ‘branch_id’ a regular column again using the reset_index function. With that, our function is ready to return the final pivot table.
15. What is melt(), and how do you use this function?
Pandas’ melt() function is part of its data reshaping functionality. It transforms or reshapes data. The melt() function unpivots a DataFrame from wide format to long format, optionally leaving identifiers set. In simple terms, it takes columns and converts them into rows, making the data long rather than wide.
Below is our demonstration of how melt() works, given a dataset df:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | foo | one | x | 1 | 10 |
| 1 | foo | one | y | 2 | 20 |
| 2 | foo | two | x | 3 | 30 |
| 3 | bar | two | y | 4 | 40 |
| 4 | bar | one | x | 5 | 50 |
| 5 | bar | one | y | 6 | 60 |
Let’s say we want to melt columns ’D’ and ‘E’ into long format with ‘A’, ‘B’, and ‘C’ as identifiers:
df_melted = df.melt(id_vars=['A', 'B', 'C'], value_vars=['D', 'E'])
The df_melted DataFrame would look like this:
| A | B | C | variable | value | |
|---|---|---|---|---|---|
| 0 | foo | one | x | D | 1 |
| 1 | foo | one | y | D | 2 |
| … | … | … | … | … | … |
| 11 | bar | one | y | D | 6 |
| 12 | foo | one | x | E | 10 |
| … | … | … | … | … | … |
| 23 | bar | one | y | E | 60 |
As seen above, the ’D’ and ‘E’ columns have been unpivoted, and their respective values are listed under the ‘value’ column. The corresponding column name (either ’D’ or ‘E’) is listed in the ‘variable’ column.
That’s the essence of the melt() function. It’s a very powerful function that’s highly useful for reshaping data, making it more suitable for further data processing or visualization.
16. When should we use Melt?
Pandas’ melt() function is particularly useful in various real-world scenarios where data needs to be restructured or reshaped for further processing, analysis, or visualization. Here are some common use-cases:
- Data Cleaning and Preprocessing: Often, datasets are provided in a wide format unsuitable for most machine learning algorithms.
melt()allows data scientists to transform these datasets into a more usable, long format. - Data Visualization: Some libraries (e.g., Seaborn or Matplotlib) might require data in long format for specific types of plots, such as box plots, violin plots, or point plots. In such cases,
melt()can be used to rearrange the data. - Statistical Analysis and Modeling: Certain statistical tests and models (e.g., ANOVA or linear regression with categorical variables) require data to be in long format. Using
melt()makes preparing data for such tests and models easier.
17. How do you handle missing data in Pandas?
Missing data is a ubiquitous problem encountered by data scientists, analysts, and engineers daily. Fortunately, Pandas provides powerful tools for cleaning datasets, enabling you to eliminate or supplement missing data from your DataFrame.
Representation of Missing Data in Pandas
Understanding how missing data is represented in Pandas is crucial. Typically, missing data in Pandas is signified by the NaN (Not a Number, of floating type) and None (object type, represents a singleton) keywords.
Checking for Missing Data
Pandas provides the isnull() and notnull() functions to check for missing data. These functions return a Boolean DataFrame that indicates missing data’s presence (or absence).
Handling Missing Data
To deal with missing data, you can use several handy functions that Pandas provides:
fillna(): This function allows you to fill missing values (i.e.,NaNorNone). You can replace all instances with a specific value or use themethodparameter to replace all null values with the last observed valid ones (forward fill) or the next observed valid ones (backward fill). This method offers great flexibility in modifying missing values.replace(): This function allows you to replace specified values in the DataFrame. It is often used with missing data to replaceNaNorNonewith a specific value.dropna(): This function allows you to drop rows or columns with missing values. It is handy when you want to remove instances of missing data from your DataFrame.interpolate(): This function provides the ability to perform interpolations (i.e., compute and fill missing values based on other values in your DataFrame). This is useful for time-series data where missing values can be filled by linearly interpolating between other points.
18. What is groupby() and how can you use it effectively to create aggregations?
Pandas groupby() is a versatile function that plays a crucial role in any data analysis workflow. This function helps group your data by certain criteria (often categorical in nature) and apply aggregate functions to these groups.
Basic Syntax
The basic syntax of groupby() function is as follows:
df.groupby('column1').aggregate_function()
Here, column1 is the column you want to group by, and aggregate_function() is any aggregate function like mean, sum, count etc.
Let’s demonstrate this with an example. We’ll use a simple dataset of student scores.
| Student | Subject | Score |
|---|---|---|
| 0 | John | Math |
| 1 | Anna | Math |
| 2 | John | Science |
| 3 | Anna | Science |
| 4 | John | Art |
| 5 | Anna | Art |
If we want to know the average score of each student across all subjects, we can use groupby() as follows:
df.groupby('Student')['Score'].mean()
This will output:
| Student | Score |
|---|---|
| Anna | 89.0 |
| John | 84.33 |
In the code above, we grouped the data by the ‘Student’ column and calculated each student’s mean score.
19. Monthly Customer Report
Write a query to show the number of users, number of transactions placed, and total order amount per month in the year 2020. Assume that we are only interested in the monthly reports for a single year (January-December).
Solution
We only need the transactions and products tables to compute the number of customers, transactions, and total order amount per month. The transactions table contains user_id, so the users table isn’t required. We join the transactions and products tables to count distinct users for the number of customers, count transaction IDs for the number of transactions, and sum the product of quantity and price for the total order amount. We group these results by the month extracted from the created_at field.
Advanced Pandas Interview Questions
20. What is time series data in Pandas? What are the problems correlated with time series data?
Time series data refers to a sequence of data indexed in chronological order. Most analysis techniques handle time series in data via a set of predefined intervals, such as daily, weekly, monthly, or yearly.
However, data does not necessarily come in well-organized intervals. Rather, it can be sporadic and unpredictable. Moreover, some data may be missing, which requires handling. These are the problems typically associated with time series data in Pandas:
- Data alignment: Time series data from different sources or with different frequencies may need to be aligned to a common frequency or index. Pandas offers functionalities like resampling and reindexing to align data properly, allowing for meaningful analysis and comparison. Data alignment methods can cause missing values, which is, coincidentally, one of the main concerns when handling time series data.
- Missing values: Most time series data is sporadic, and data alignment methods such as resampling can cause the appearance of missing values where certain time points do not have corresponding observations. Dealing with missing values requires imputation techniques or appropriate handling of them during analysis. Outliers:** While not inherently tied to time series data, outliers can distort the analysis and need to be identified and handled appropriately. Outliers are extreme values that deviate significantly from the normal pattern.
21. How can we perform time series data alignment with Pandas?
In Pandas, time series data alignment can be performed using various techniques, such as resampling and reindexing. In this section, we will focus on resampling as a method to handle data alignment in time series data.
Resampling is the process of changing the frequency of the time series data. It allows us to convert the data to a different frequency, such as upsampling (increasing frequency) or downsampling (decreasing frequency). Resampling is particularly useful when dealing with time series data that have different sampling rates or irregular intervals.
Pandas provides the resample() method, which is used to perform resampling on a time series object. The resample() method is followed by an aggregation function that specifies how to summarize or combine the data within each new interval. Here’s an example:
# given that our DataFrame df has time series data with weekly intervals
monthly_data = df.resample('M').mean() # downsampling
daily_data = df.resample('D').ffill() #upsampling
22. What is the difference between Upsampling and Downsampling?
Downsampling and upsampling are both techniques used when resampling time series data. Upsampling is the process of increasing the granularity of time series data. In our last code snippet, for example, we can see that we are resampling our data from a weekly frequency to a daily frequency with the string ‘D’.
On the other hand, the opposite is true for downsampling, which involves decreasing the granularity of time series data. Referencing to our previous code block again, resampling our weekly time series data to monthly (denoted by 'M') is an example of downsampling.
23. How do we handle the problems associated with Downsampling and Upsampling?
Each resampling method comes with its own potential problems. Let’s take DataFrame df, for example:
| Date | Amount |
|---|---|
| 28/06/2023 | 2452 |
| 29/07/2023 | 601 |
| 7/07/2023 | 256 |
| 16/07/2023 | 5126 |
When we resample this dataframe with *df.resample('W')* for example, we encounter two problems: missing data and data aliasing.
1. Data Aliasing
Data aliasing occurs when multiple original data points are mapped to the same target frequency bin during downsampling. This can lead to inaccurate representations of the data and loss of information.
We can use different aggregation functions to summarize the data within each target frequency bin to handle data aliasing. In the following data points:
| Date | Amount |
|---|---|
| 28/06/2023 | 2452 |
| 29/07/2023 | 601 |
We can see that both of these dates can be mapped to the same week. To settle this, you must use an aggregation method to merge these two values. The aggregation methods .sum() ,.mean() , and .count() are commonly used to handle data aliasing.
When using .sum() the result of df.resample('W')**.**sum() would be:
| Date | Amount |
|---|---|
| 25/06/2023 | 1526.5 |
| 02/07/2023 | 256 |
| 09/07/2023 | NaN |
| 16/07/2023 | 5126 |
2. Missing Data via Data Interpolation
Missing data can occur during upsampling when gaps or missing values exist in the original data. Upsampling involves increasing the frequency or granularity of the data, which can result in periods without any data. To handle missing data, we can use data interpolation techniques.
Data interpolation is the process of estimating values for the missing data points based on the available data. Different interpolation methods are available, such as linear interpolation, polynomial interpolation, spline interpolation, and more. These methods aim to fill in the missing values by estimating them based on the neighboring data points.
For example, let’s consider the following resampled DataFrame:
| Date | Amount |
|---|---|
| 25/06/2023 | 1526.5 |
| 02/07/2023 | 256 |
| 09/07/2023 | NaN |
| 16/07/2023 | 5126 |
In this case, the week starting on 09/07/2023 has no data available. To handle this missing data, we can use interpolation to estimate the value for that week based on the neighboring data points. For instance, we can use linear interpolation, which estimates the neighboring points’ missing value as a linear function. We can use df.resample('W').sum().interpolate(method='linear') and the result would be:
| Date | Amount |
|---|---|
| 25/06/2023 | 1526.5 |
| 02/07/2023 | 256 |
| 09/07/2023 | 2691 |
| 16/07/2023 | 5126 |
We have now filled in the missing value for the week starting on 09/07/2023 by using interpolation.
24. Practical Question: Interpolating Missing Temperatures
The category for this question is: Interpolation
You are working for a climate research organization and are given a timeseries dataframe that has daily temperature readings for different cities. The dataframe has three columns: date, city, and temperature.
Due to some data recording issues, the temperature readings for some days might be missing. The organization requires the temperature readings for each day, so you must interpolate the missing data.
Write a Python function using Pandas that performs this interpolation.
Clarification:
- Interpolation should be done on a city basis. The interpolation should consider only the same city data to estimate the missing values.
- The interpolation method should be linear interpolation.
Example:
Input:
| date | city | temperature |
|---|---|---|
| 2023-01-01 | London | 10 |
| 2023-01-02 | London | NaN |
| 2023-01-03 | London | 12 |
| 2023-01-04 | London | NaN |
| 2023-01-05 | London | 14 |
| 2023-01-01 | Berlin | -2 |
| 2023-01-02 | Berlin | -1 |
| 2023-01-03 | Berlin | NaN |
| 2023-01-04 | Berlin | 1 |
| 2023-01-05 | Berlin | 2 |
Output:
| date | city | temperature |
|---|---|---|
| 2023-01-01 | London | 10 |
| 2023-01-02 | London | 11 |
| 2023-01-03 | London | 12 |
| 2023-01-04 | London | 13 |
| 2023-01-05 | London | 14 |
| 2023-01-01 | Berlin | -2 |
| 2023-01-02 | Berlin | -1 |
| 2023-01-03 | Berlin | 0 |
| 2023-01-04 | Berlin | 1 |
| 2023-01-05 | Berlin | 2 |
Solution
To solve this question, we separate our process into several parts. First, we should clean and prepare our data, ensuring that they are all in the correct formats and data types. Then, we perform the interpolation using the .interpolate(method='linear') function to execute the interpolation.
- Convert the ‘temperature’ column to float type:
temperature_data['temperature'] = temperature_data['temperature'].astype(float)
This step ensures that the ‘temperature’ column is treated as numerical data.
- Convert the ‘date’ column to datetime format:
temperature_data['date'] = pd.to_datetime(temperature_data['date'])
Converting the ‘date’ column to datetime format enables easier manipulation and sorting of the dates.
- Format the ‘date’ column to ‘YYYY-MM-DD’:
temperature_data['date'] = temperature_data['date'].dt.strftime('%Y-%m-%d')
This step ensures that the ‘date’ column is formatted consistently as ‘YYYY-MM-DD’ for better readability and uniformity.
- Convert ‘city’ to a categorical variable:
temperature_data['city'] = pd.Categorical(temperature_data['city'], categories=temperature_data['city'].unique(), ordered=True)
Converting ‘city’ to a categorical variable assigns unique categories to each city in the order they appear in the input data. This is useful for later sorting and grouping.
- Sort the data by ‘city’ and ‘date’:
temperature_data.sort_values(by=['city', 'date'], inplace=True)
Sorting the data ensures that the subsequent interpolation is applied correctly within each city and across dates.
- Group the data by ‘city’ and apply linear interpolation to ‘temperature’:
temperature_data['temperature'] = temperature_data.groupby('city').apply(
lambda group: group['temperature'] if group['temperature'].isna().all() else group['temperature'].interpolate(method='linear')).values
This step groups the data by ‘city’ and applies linear interpolation to each group’s ‘temperature’ column.
The interpolation is only applied if not all values in the group are NaN. The interpolation method used here is ‘linear’, which fills in missing values with interpolated values based on neighboring data points.
Then, we should end up with the following code:
import pandas as pd
def interpolating_missing_temperatures(temperature_data: pd.DataFrame) -> pd.DataFrame:
temperature_data['temperature'] = temperature_data['temperature'].astype(float)
temperature_data['date'] = pd.to_datetime(temperature_data['date'])
temperature_data['date'] = temperature_data['date'].dt.strftime('%Y-%m-%d')
temperature_data['city'] = pd.Categorical(temperature_data['city'], categories=temperature_data['city'].unique(), ordered=True)
temperature_data.sort_values(by=['city', 'date'], inplace=True)
temperature_data['temperature'] = temperature_data.groupby('city').apply(
lambda group: group['temperature'] if group['temperature'].isna().all() else group['temperature'].interpolate(method='linear')).values
return temperature_data
Try These Difficult Practical Questions
25. Practical Question: Random Forest From Scratch
The category for this question is: Random Forests
Build a random forest model from scratch with the following conditions:
- The model takes as input a dataframe
dataand an arraynew_pointwith length equal to the number of fields in thedata - All values of both
dataandnew_pointare0or1, i.e., all fields are dummy variables and there are only two classes - Rather than randomly deciding what subspace of the data each tree in the forest will use like usual, make your forest out of decision trees that go through every permutation of the value columns of the data frame and split the data according to the value seen in
new_pointfor that column - Return the majority vote on the class of
new_point - You may use
pandasandNumPybut NOTscikit-learn
Bonus: The permutations in the itertools package can help you easily get all of any iterable object.
Example:
Input:
new_point = [0,1,0,1]
print(data)
...
Var1 Var2 Var3 Var4 Target
0 1.0 1.0 1.0 0.0 1
1 0.0 0.0 0.0 0.0 0
2 1.0 0.0 1.0 0.0 0
3 0.0 1.0 1.0 1.0 1
4 1.0 0.0 1.0 0.0 0
.. ... ... ... ... ...
95 0.0 1.0 0.0 1.0 0
96 1.0 1.0 0.0 0.0 0
97 0.0 0.0 1.0 1.0 0
98 1.0 0.0 0.0 0.0 0
99 0.0 1.0 0.0 0.0 0
[100 rows x 5 columns]
Output:
def random_forest(new_point, data) -> 0
26. First Names Only
You’re given a dataframe containing a list of user IDs and their full names (e.g. ‘James Emerson’).
Transform this dataframe into a dataframe containing the user IDs and only each user’s first name.
Example:
Input:
| user_id | name |
| --- | --- |
| 1034 | James Emerson |
| 9430 | Fiona Woodward |
| 7281 | Alvin Gross |
| 5264 | Deborah Handler |
| 8995 | Leah Xue |
Output:
| user_id | name |
| --- | --- |
| 1034 | James |
| 9430 | Fiona |
| 7281 | Alvin |
| 5264 | Deborah |
| 8995 | Leah |
27. T-value via Pandas
Here’s the top-voted answer from our community:
The t-value measures the size of the difference relative to the variation in your sample data. Put another way, T is simply the calculated difference represented in standard error units. The greater the magnitude of T, the greater the evidence against the null hypothesis. This means there is greater evidence that there is a significant difference. The closer T is to 0, the more likely there isn’t a significant difference.
In Python, the implementation can be done this way:
import pandas as pd
def t_score(df,mu0):
mean = df.mean()
std = df.std()
sqrt = pow(df.count(), 0.5)
strength_signal = mean - mu0
noise = std/sqrt
# Calculate t-value
t_stat = strength_signal/noise
return t_stat