

Top 27 Database Design Interview Questions (Updated for 2024)

Overview
Database design interview questions test a candidate’s ability to build and design databases based on stakeholder inputs.
Database design questions are often framed as hypothetical case studies or SQL coding questions. During interviews, however, you might also face basic database questions or SQL scenario-based interview questions.
The most common types of database design interview questions include:
- Basic definitions, concepts and database design - These questions test basic database design concepts, such as entity relationship modeling or the normalization forms. Keep your answers short and simple.
- Case study questions - These questions provide a problem statement like: How would you build a database for X feature on Y platform? You must first gather information and then develop a schema and database architecture to fit the problem.
- Database coding questions - SQL coding exercises (especially focused on Data Definition Language statements) will be asked about. These questions test your familiarity with SQL.
- Scenario-based questions - These questions propose a database issue, and ask you how you would respond, e.g. what would you do if you suspect a data error? Your job is to walk the interviewer through your problem-solving process.
For a more comprehensive guide on how to answer these questions, check out the Data Engineering Learning Path.
What is Database Design?

In the simplest terms, database design is the process of creating a normalized database from scratch to hold data. Therefore, database design is one of the most common concepts identified in data engineer interview questions, and can also be often found in machine learning and business intelligence engineer interviews.
Database design involves choosing what data is going to be stored, where it will be stored and how it will be stored. Additionally, the database designer will divide raw data into tables, define relationships between different entities in the data, normalize data so the end user can easily track, understand and derive insights from the data.
Database design professionals are also responsible for such fields as:
- Database security.
- Data replication.
- Availability of data.
- Database partitioning).
- Data backup.

Basic Definitions, Concepts and Database Design Interview Questions
These interview questions are framed in two ways most commonly:
- Explain X concept.
- What is the difference between X and Y?
This type of interview question can cover a wide range of topics, from conceptual data models, to SQL DDL statements to straight definitions. Whatever the question, keep your answers short and simple. Demonstrate your understanding of the topic, then allow the interviewer to move on to the next question.
1. What is the difference between a physical database model and a logical model?
The physical database model is the last step before implementation, and it includes a plan for building the database. The logical database model is more hypothetical and closer to a map of the entity relationships. A big difference is that physical models are DBMS-specific, while logical models are not. Additionally, physical models have specific features like security, table structures and constraints.
2. What is data modeling? How experienced are you with it?
With this question, provide a brief definition of data modeling, and then talk about your most recent work in modeling. You might say:
“Data modeling is typically the first step in database design, in which the designer first creates a conceptual model of how data items relate to each other. In my most recent job I designed a variety of databases for both analytics and data storage. I have also worked with both star and snowflake schema.”
3. What features are in the physical data model?
Here is an overview of the features in physical models:
- Specifying all tables and columns.
- Foreign keys to identify relationships between tables.
- Denormalization may occur based on user requirements.
- Physical considerations may cause the physical data model to be quite different from the logical data model.
- Physical data models will be different for different RDBMS. For example, data type for a column may be different between MySQL and SQL Server.
4. Which is better: star or snowflake schema?
With questions like “which is better,” you should first understand the use case. Star schemas include one or more fact tables, which are used to index dimension tables.
Star schema is generally better for simpler relational databases, like data marts. Snowflake schema uses less space for storing dimension tables, but are typically more complex. One advantage is that snowflake models do include redundant data, and are easier to maintain, which is why they are better suited for data warehouses.
5. What is the primary key of a database?
A primary key is a keyword in a relational database that is unique for each record. Therefore, a primary key is NOT NULL and is also UNIQUE. Examples include records like driver license number, customer ID number, telephone number or patient ID. Relational databases only have one primary key.
6. What is data normalization? What is denormalization?
Data normalization is the process of organizing and formatting data to appear similar across all records and fields. Data normalization helps provide more efficient and clearer navigation for analysts, as duplicate data is removed and referential integrity is maintained.
Denormalization, on the other hand, is a database technique in which redundant data is added to one or more tables. This is used to optimize performance, as it can reduce the need for costly joins.
7. What are the normal forms in database design?
The normal forms in database management systems refer to the stages of normalization. For example, there are three main normal forms: 1NF, 2NF and 3NF.
A table in the first stage (1NF) meets these requirements:
- Columns have single value s.
- Columns have unique names.
- Attribute values all have the same data type.
- No two records are identical.
8. What are key differences between the star and snowflake schema?
Star schema is simpler, and the basic architecture is a fact table in the middle that references multiple dimension tables. All of the dimension tables connect to the fact table, and the primary keys in the dimension tables are foreign keys in the fact table.
With snowflake schema, normalization increases. The fact table is similar to a star schema, but the dimension tables are normalized. Therefore, the architecture looks similar to an actual snowflake.
Some differences include:
- Star schema is denormalized, and requires fewer joins.
- Queries tend to be faster in star schema.
- Snowflake does not contain redundant data and is easy to maintain.
Case Study Database Design Interview Questions
This is the most common type of database design interview question. You will be provided with database requirements, then you must develop the schema and architecture for that database. Here is an example database design case study question: How would you design a schema for storing song information on iTunes?
First, you would want to figure out what information is necessary for the database, as well as the purpose for the data. We might ask questions like:
- Do we care about album title, artist, song, song length, genre, or all of the above? Why?
- What are we looking to gain from storing song information?
- Are we collecting data for a business purpose? Are we trying to build a recommendation engine?
- How much data do we have?
Clarifying questions narrow the field of concerns we are responsible for addressing. This allows us to approach the question with real depth instead of treating a great variety of possible subjects lightly. Once we have our bedrock of actionable information, we can build out the hypothetical schema based on the fundamentals of database design.
Database design is a common concept covered in data engineer case study interviews, and the process is similar: Get clarification, state assumptions, propose a solution, and consider the tradeoffs.
9. How would you create a schema to represent client click data on the web?
Let’s also say the schema is for analytics. Therefore, one of the first steps would be to represent each action with a specific label. In this case, assigning each click event a name or label describing its specific action.
For example, we can say the product is Dropbox and that we want to track each folder by clicking on the UI of an individual person’s Dropbox account. We can label the clicking on a folder as an action name called folder_click. When the user clicks on the side panel to log in or logout and we need to specify the action, we can call it login_click and logout_click.
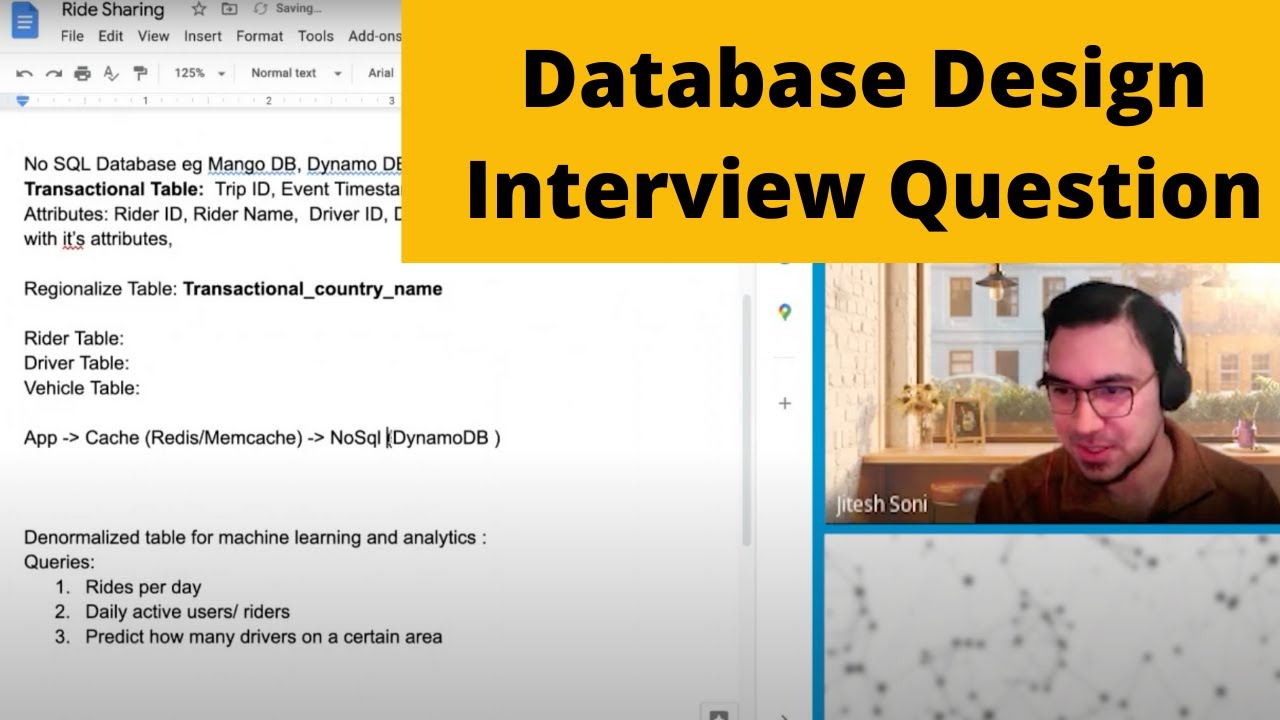
10. How would you design a database that could record rides between riders and drivers for a ride-sharing app?
Follow up question: What would the table schema look like? See a full mock interview solution for this database design question on YouTube:
11. How would you design the database schema for a Yelp-like app?
Hint: The schema should indicate the following:
- The table name.
- The names of columns/fields.
- The data type of each column/field.
- A list of constraints on values (primary or foreign keys).
- A short description of each column/field.
Make sure to elaborate on how the tables join with each other. In this question, you might have two tables, restaurants and reviews.
12. How would you design the data model for the notification system of a Reddit-style app?
This is the type of question you would face in a data engineering case study interview. Your goal is to walk the interviewer through a data model. One of the first steps when answering this question is to ask some clarifying questions like: what types of notifications are we engaged with, e.g. trigger-based or scheduled notifications?
Once you have that clarification, you can then design a simple database. There might be two tables in the database:
- Notifications (name and type of notification)
- Notification metrics (time sent, reads, clicks, deliveries).
13. Design a database for a Tinder-style dating app. What does the schema look like?
First, approach this problem by understanding the scope of the dating app and what functionality we must design around.
If we were to list the key Tinder app capabilities, it would be something like:
- Onboarding - The user opens up the app, adds their preferences, adds profile pictures and starts swiping on users.
- Matching - If the user matches with another user, we notify the users and create a messaging system. A match is defined as a double opt-in transaction between two users.
- Messaging - Users can message each other only if both have been matched. Users can also leave conversations at any time.
The next step would be to figure out if we have specific feature goals that we have to account for within engineering and system design and continue to improve the proposed schema.
14. Design a podcast search engine with transcript and metadata.
With this question, you want to start with some clarifying questions like:
- How is the search accessed? Voice? Text?
- How many searches are conducted via text search?
- Who uses this search engine? Is this a user-facing feature?
- Is a machine-learning solution really needed?
15. How would you optimize finding the top 10 closest related jobs for millions of new jobs per day?
See the full video solution here:

16. How would you design a machine learning system to reduce incorrect or missing orders?
To reduce incorrect orders, design a binary classification model to predict order cancellations. The user will receive in-app notifications for potential errors when selecting a restaurant and at checkout. Usually, mistakes arise from GPS address mismatches, long pick-up distances, large order quantities, and/or timing issues.
This model will consider historical user orders, geolocation differences, merchant hours, and order details. Balancing precision and recall is crucial; over-alerting might deter purchases. After offline validation, the system’s effectiveness is assessed via A/B testing among frequent users, focusing on cancellation rates and monitoring revenue impacts.
17. How would you design a database for a payment management system?
You’re tasked with designing a database system for Swipe Inc., a company that manages payments for software developers. Swipe manages a set of APIs so developers can abstract payment processes for their web service and transfer control over to Swipe’s APIs to manage payment security and finance handling.
Since Swipe Inc is a fintech handling web service APIs, it requires a database adept in API processing, JSON compatibility (possibly MongoDB), and SQL for data analysis. Its features should include data encryption, machine learning for fraud detection, and interfaces with payment processors and banks. Key non-functional needs are flexibility, upgradability, and speed for customer retention.
18. How would you create a product that predicts the number of daily transit riders of the New York City Subway at a given hour?
Your team is tasked to create a product that predicts the number of daily transit riders of the New York City Subway at a given hour. You’ll receive hourly data supplied from your client’s database to use as training data for supplementing your current AI’s working dataset. Predictions should be delivered on an hourly basis.
How would you create this project?
Hint: Most of the products’ functional requirements are stated in the question. But what about its non-functional requirements?
Coding Database Design Interview Questions

During the technical and on-site rounds, you will likely be required to demonstrate proficiency via coding exercises. For database design, that means that you will be expected to know your way around SQL, especially Data Definition Language.
An interviewer may also throw some querying questions your way to make sure that you are familiar enough with SQL to understand the needs of the people who will eventually be using the database(s) you design.
In the database design interview, you may be asked more specialized questions that have to do with systems design and be expected to respond with an answer that takes the interviewer through the steps you would follow from the conceptual level of the problem to its physical solution.
19. What is the difference between DELETE and TRUNCATE?
Although they are both used to delete data, a key difference is that DELETE is a Database Manipulation Language (DML) command, while TRUNCATE is a Data Definition Language (DDL) command.
Therefore, DELETE is used to remove specific data from a table, while TRUNCATE removes all the rows of a table without maintaining the tables structure. Another difference: DELETE can be used with the WHERE clause, but TRUNCATE cannot. In this case, DELETE TABLE would remove all the data from within the table, while maintaining the table’s structure. TRUNCATE TABLE would delete the table in its entirety.
20. You are provided a database with messages sent between two users on a messaging app. What are some insights that can be derived from the table?
Follow-up questions: What do you think the distribution of the number of conversations created by each user per day looks like? Write a query to get the distribution of the number of conversations created by each user by day in 2020.
With this, you could start with some top-level insights like the total number of messages per day, the number of conversations started, and the average number of messages per conversation.
See a mock interview solution for this SQL database question on YouTube:

21. You have a database of traffic on the Golden Gate Bridge. Write a query to get the time of the fastest car to get across on the current day.
A question like this starts as a database design case study question. You are asked to define the table schema to track how long each San Francisco-bound car took to enter and exit the bridge, as well as additional data like the car model and license plate.
This question then jumps into a SQL case study, because you are asked to query the table schema you created.
In this case, we are told that we need to track the time that cars entered and exited the bridge, but also need the car make and model along with license plate information. We know that the car model to license plate information will be one-to-many, given that each license plate represents a single car, and a car model can be replicated many times.
What else would you need to do to develop a strong response to this question?
22. Write a SQL query to create an aggregate table with the song count by date for each user.
More context: We have a table called song_plays that tracks each time a user plays a song. Say we want to create an aggregation table called lifetime_plays that records the song count by date for each user. Write a SQL query that could perform this extract, transform, and load (ETL) each day.
For this problem, we use the INSERT INTO statement to add rows into the lifetime_plays table. If we set this query to run daily, it becomes a daily ETL process.
The rows we add are selected from the subquery that selects the created_at date, user_id, song_id, and count columns from the song_plays table for the current date.
We use GROUP BY because we want to have a separate count for every unique date, user_id, and song_id combination.
Scenario-Driven Database Design Interview Questions
Scenario-driven database design questions assess your approach to solving problems in either a hypothetical or a real world historic scenario.
Unlike technical questions, the goal here is not to grade you on a “right” or “wrong” answer, but to get a sense of the process you use to deal with problems without immediate solutions. The most important thing to remember when answering this sort of question is to be clear and comprehensive in your description of your approach.
When describing a solution, outline your thought process, possible alternatives that you decided against (and why you ruled them out) and the outcome.
23. How would you add a column to a table with a billion rows that inserts data from the original source, without affecting the user experience?
Before jumping into the question, we should remember to clarify a few details that we can potentially get out of the interviewer. It helps to ask questions in order to better understand the scenario, as well as show that you can think holistically about the problem. Rushing too quickly into a solution is a red flag for many interviewers.
Given the problem statement, we should clarify an important question.
What is the potential impact of downtime?
We always have to remember to get more context out of the question. In this scenario when we are talking about a table with a billion rows, this could be a table that is powering an entire company in which downtime would affect thousands of dollars in sales, or could just be an offline analytics events table that would only cause minimal impact to internal employees.
It is crucial then to probe the interviewer and assess what the potential effects of downtime are in terms of seconds, minutes and hours. Figuring out the impact is pertinent to then determining our strategy going forward.
24. How would you build a system to track changes in a database?
Explain how you would build a system to track changes in a database.
You can track changes in a database by creating a separate table that gets entries added via triggers when INSERT, UPDATE or DELETE statements are used. This is the most common method and it covers general changes performed.
You would also want to track changes by user. There are many ways to do this, but one would be to have a separate table that inserts a record every time a user updates data. This would record the user, time, and ID of the changed record.
25. How would you migrate databases with as little downtime as possible?
A question like this assesses your familiarity with this task. Start with clarifying questions about the database, and the migration project. How big is the database? What is it used for? Then outline a migration strategy. You might outline a two-write process, for example, in which you set up a new database and write to both the old and new databases. During the migration, the old database would be used for reading.
Then, you could backfill all data from the old database to the new database, and then update the code to read from the new database. Ultimately, after testing, you can move both read and write to the new database.
26. How would you create or modify a schema to keep track of these address changes?
More context: You are tasked with keeping track of a customer’s addresses in your database. However, a customer’s address changes whenever they move. We want to keep track of their moving history as well as the person that moves in afterwards.
You might start with this: Say we started out with a 1 to 1 relationship with users to addresses in the customers table. How would we modify that as customers move and new customers are added?
27. Describe a database project you worked on. What schema did you use and why?
Start by describing the differences between schemas and why you might use one over the other. For example, you could say:
“I was developing a database for an e-commerce company, and the goal was to do analysis across a variety of dimensions for reporting purposes. I chose the snowflake schema because it could handle the complexity, but also because it reduced memory consumption.”
More Database Design Interview Resources
Interview Query offers a variety of resources to prepare for database design interviews:
- The Data Engineering Learning Path to sharpen your skills and learn to tackle data engineering interview questions.
- The job board showing recent openings and company interview guides to help you prepare.
- The list of database design interview questions, as well as the list of SQL Interview Questions, to help you practice for your next interview.
- Individual coaching sessions with our experts.
Often, database design questions look similar to data engineer case studies. Therefore, practice a variety of engineering case studies prior to the interview.